
Research
Fundamental interpretability research to understand and intentionally design advanced AI systems
Filter By
Predictive Data Debugging: Reveal and Shape What Your Model Learns, Before You Train
Predictive Data Debugging: Reveal and Shape What Your Model Learns, Before You Train
Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention


Predicting Rare LLM Failures with 30× Fewer Rollouts
Predicting Rare LLM Failures with 30× Fewer Rollouts
Steering Along Manifolds to Control Neural Networks
Steering Along Manifolds to Control Neural Networks


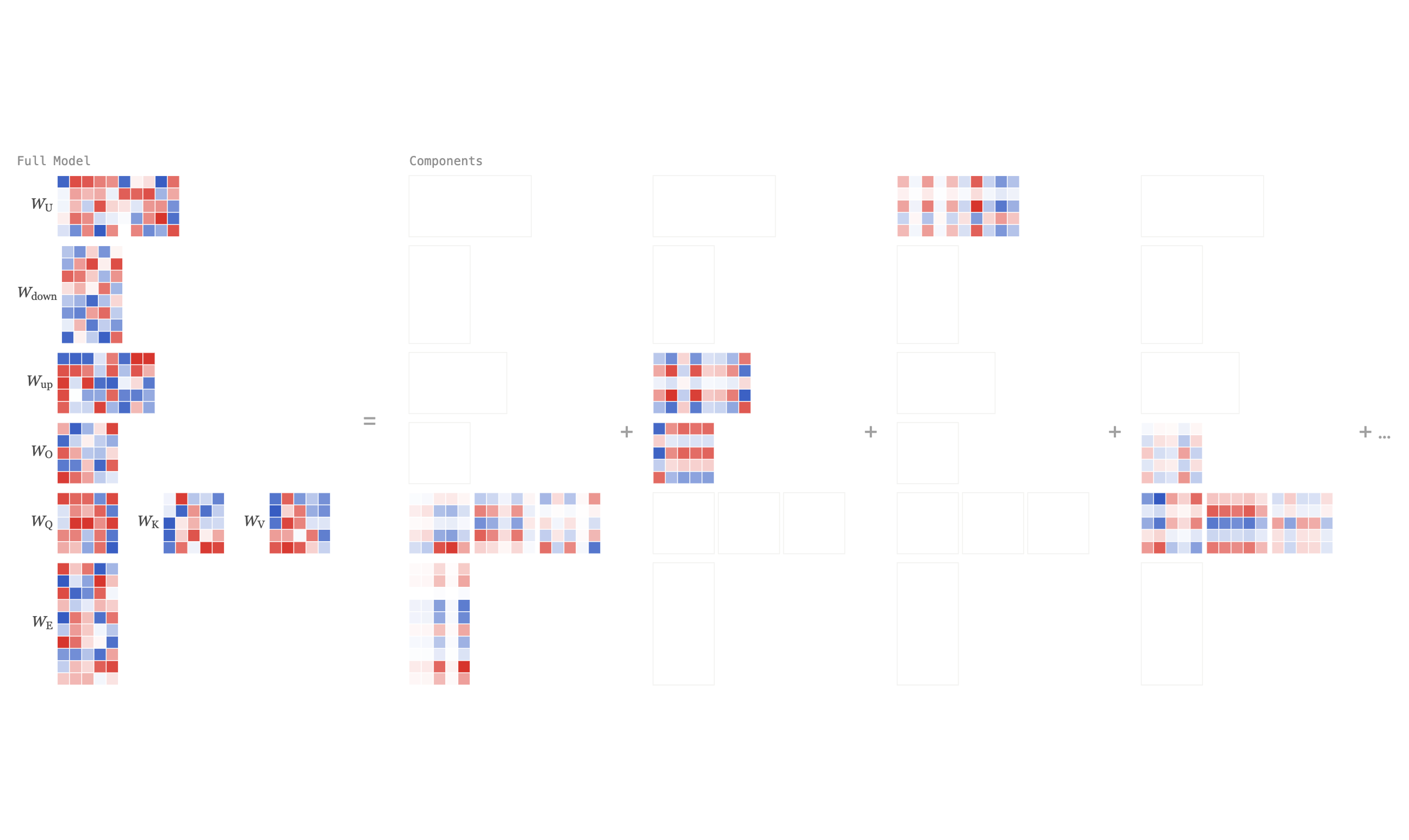
Paper Summary: Interpreting Language Model Parameters
Paper Summary: Interpreting Language Model Parameters

Verbalized Eval Awareness Inflates Measured Safety
Verbalized Eval Awareness Inflates Measured Safety

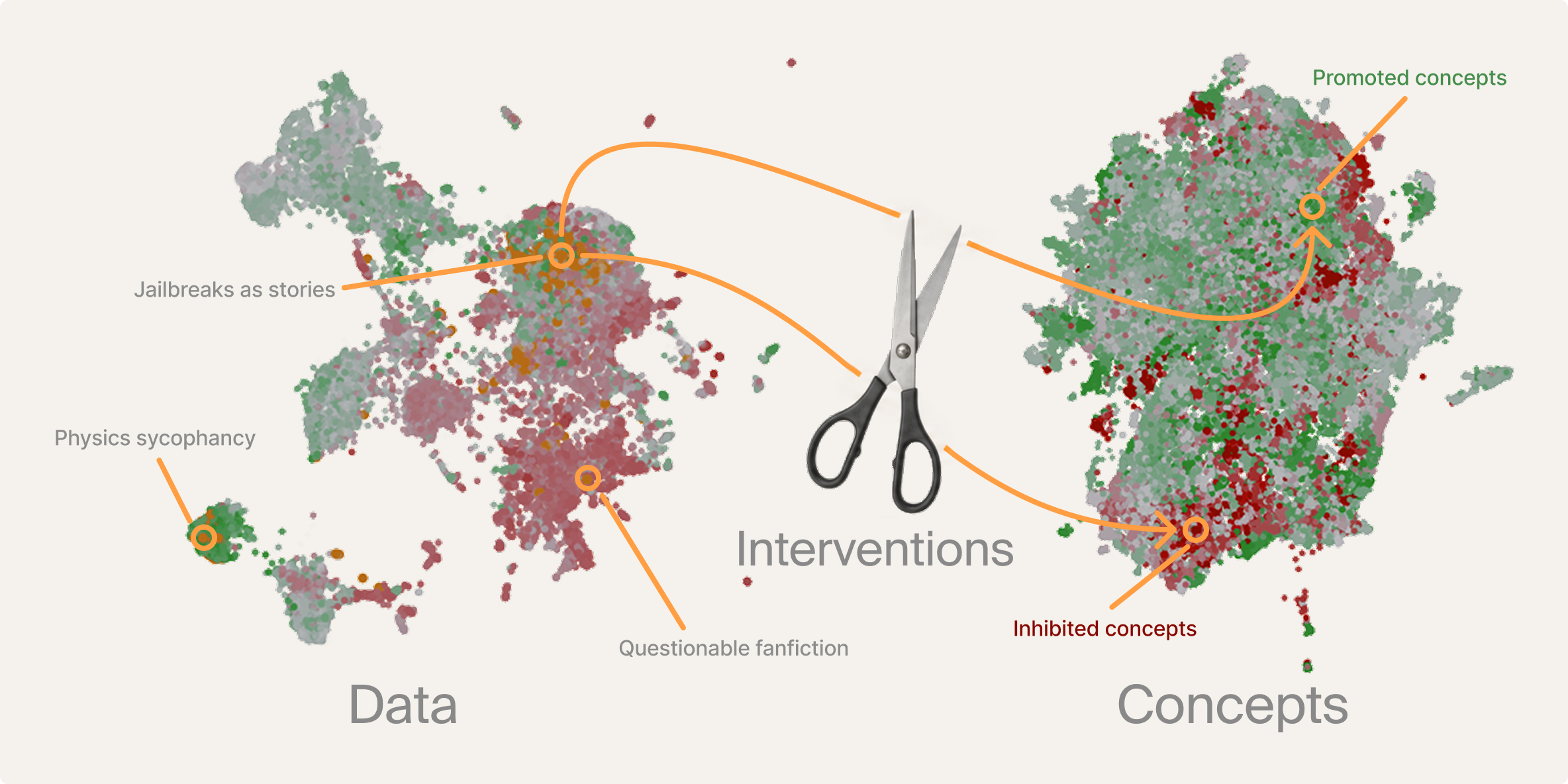
Probe-Based Data Attribution: Surfacing and Mitigating Undesirable Behaviors in LLM Post-Training
Probe-Based Data Attribution: Surfacing and Mitigating Undesirable Behaviors in LLM Post-Training

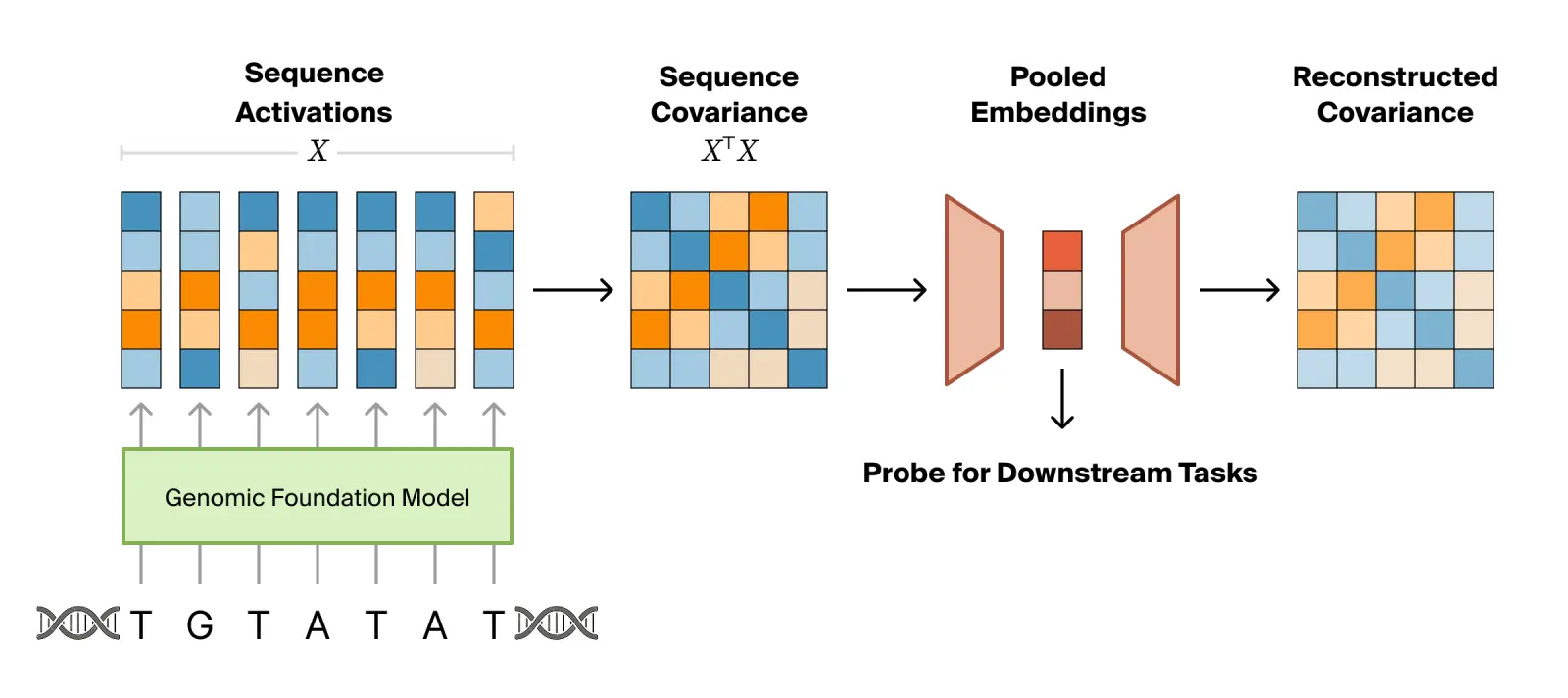
Explaining 4.2 million genetic variants with state-of-the-art, interpretable predictions
Explaining 4.2 million genetic variants with state-of-the-art, interpretable predictions
Using Self-Correcting Search to Accelerate Materials Discovery
Using Self-Correcting Search to Accelerate Materials Discovery

Reasoning Theater: Probing for Performative Chain-of-Thought
Reasoning Theater: Probing for Performative Chain-of-Thought

Features as Rewards: Using Interpretability to Reduce Hallucinations
Features as Rewards: Using Interpretability to Reduce Hallucinations

Using Interpretability to Identify a Novel Class of Alzheimer's Biomarkers
Using Interpretability to Identify a Novel Class of Alzheimer's Biomarkers
Priors in Time: Missing Inductive Biases for Language Model Interpretability
Priors in Time: Missing Inductive Biases for Language Model Interpretability
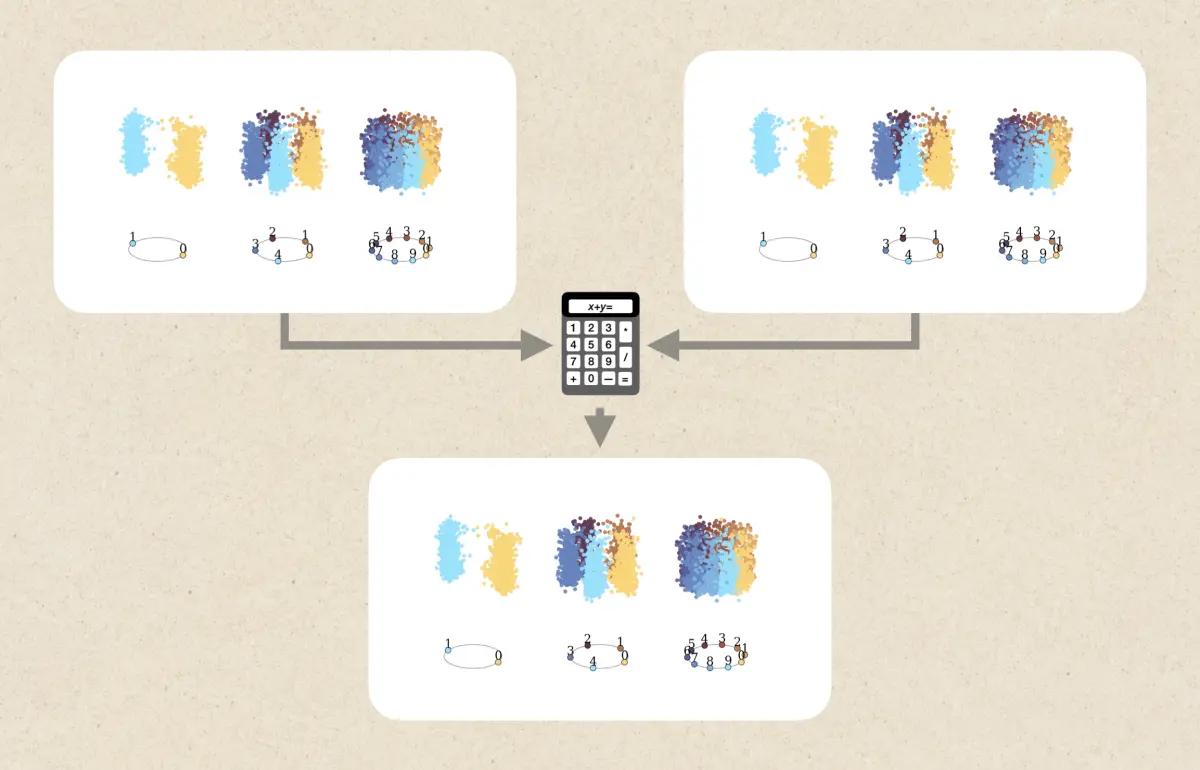
Belief Dynamics Reveal the Dual Nature of In-Context Learning and Activation Steering
Belief Dynamics Reveal the Dual Nature of In-Context Learning and Activation Steering
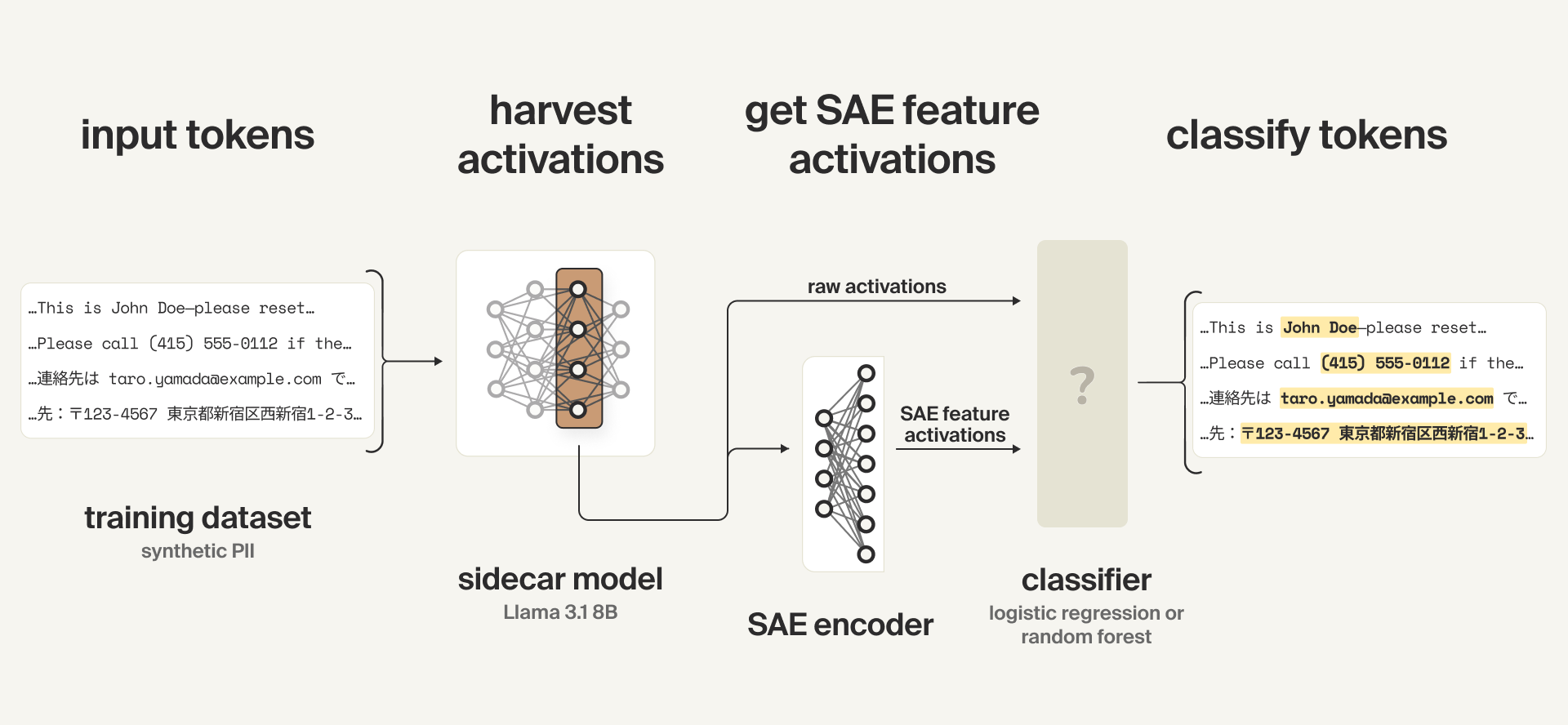
Deploying Interpretability to Production with Rakuten: SAE Probes for PII Detection
Deploying Interpretability to Production with Rakuten: SAE Probes for PII Detection
Mixing Mechanisms: How Language Models Retrieve Bound Entities In-Context
Mixing Mechanisms: How Language Models Retrieve Bound Entities In-Context
Understanding Sparse Autoencoder Scaling in the Presence of Feature Manifolds
Understanding Sparse Autoencoder Scaling in the Presence of Feature Manifolds
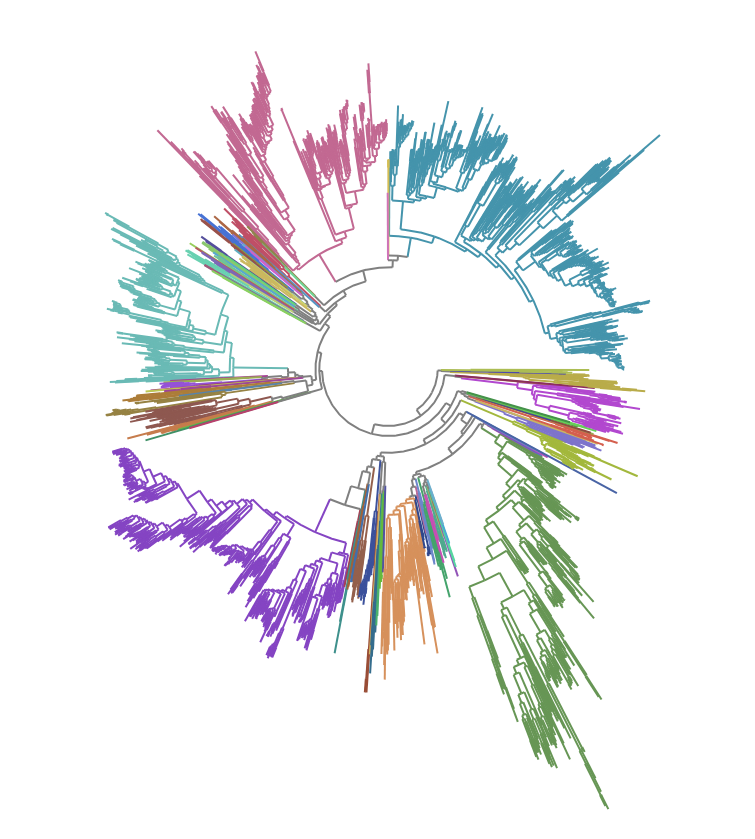
Adversarial Examples Are Not Bugs, They Are Superposition
Adversarial Examples Are Not Bugs, They Are Superposition
Discovering Undesired Rare Behaviors via Model Diff Amplification
Discovering Undesired Rare Behaviors via Model Diff Amplification
The Circuits Research Landscape: Results and Perspectives
The Circuits Research Landscape: Results and Perspectives

Replicating Circuit Tracing for a Simple Known Mechanism
Replicating Circuit Tracing for a Simple Known Mechanism
Painting With Concepts Using Diffusion Model Latents
Painting With Concepts Using Diffusion Model Latents



Contact us
Interested in partnering with Goodfire?