
The World Inside Neural Networks
How neural geometry will unlock understanding and control of AI
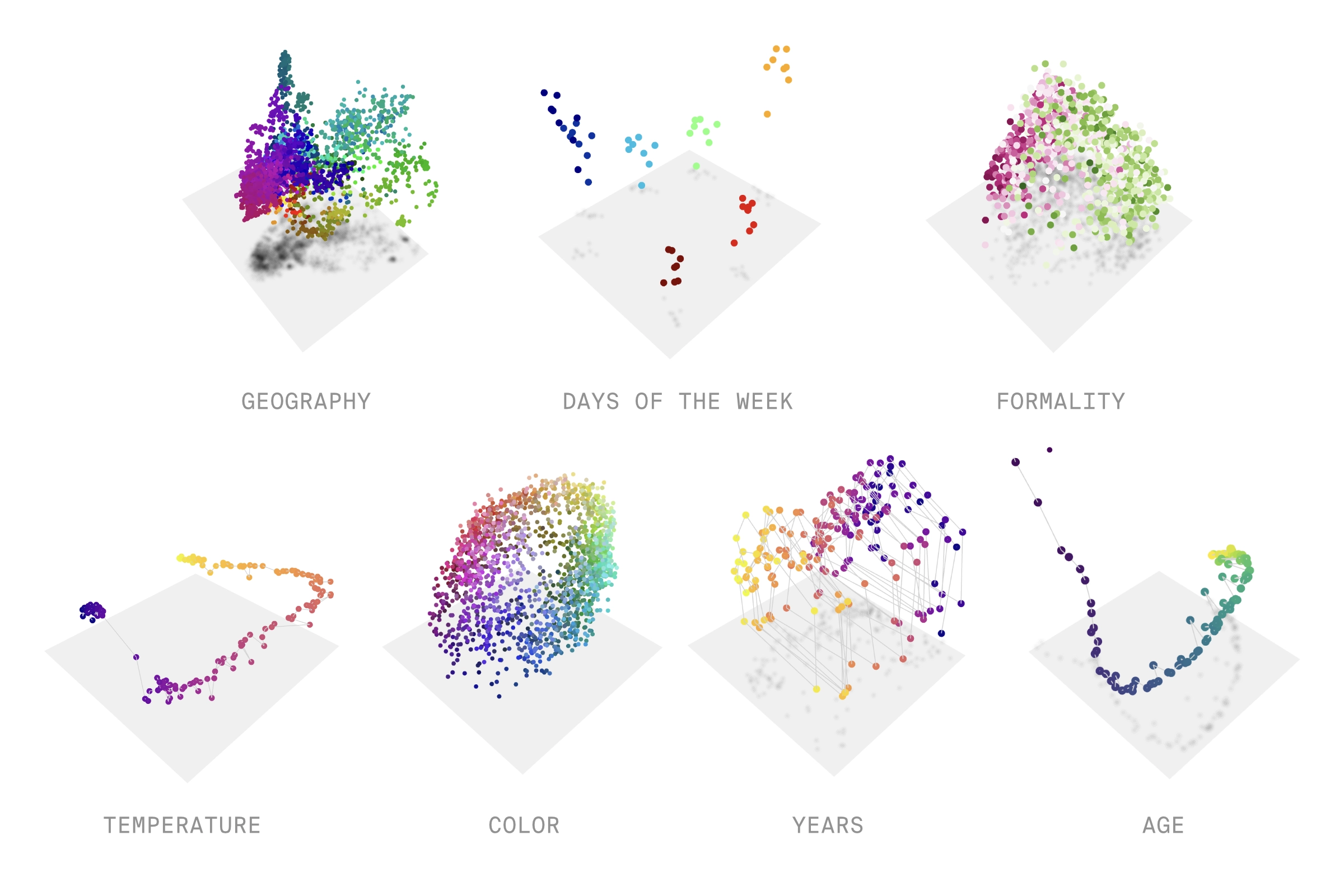
Our world is full of objects and richly structured geometric relationships—the color wheel, road networks, family trees, months of the year—and humans use structured mental concepts to represent and navigate this complex reality[1]Seung, 1999, Behrens et al., 2018, Sohn et al., 2019, Chung & Abbott, 2021, Kriegeskorte & Wei, 2021, Khona & Fiete, 2022.
We also know that the inner world of neural networks is full of structure that reflects the structure of the outer world. This is true across models, modalities, and domains: In the internal representations of language models, numbers[2]Nanda et al. 2023, Zhong et al. 2023, Zhou et al. 2024, Zhou et al. 2025, Kantamneni and Tegmark 2025, Levy and Geva 2025, Fu et al. 2026, days of the week, and months of the year[3]Engels et al. 2024, Modell et al. 2025, Karkada et al. 2026, Prieto et al. 2026 are circular loops, and smooth curves represent the years in history[4]Engels et al. 2024, Modell et al. 2025 and characters in a line of text[5]Gurnee et al. 2025. In image models, objects' spatial arrangement is recapitulated in activation space[6]Fel et al. 2025a and colors are represented on smooth surfaces structured by hue, saturation, and lightness[7]Flachot et al. 2022, Pach et al. 2026, Yeh et al. 2025. In a genomic model, the entire tree of life lies on a complex manifold[8]Pearce et al. 2025, and we discovered a previously-unknown class of Alzheimer's biomarkers as a clean curve in an epigenomic model[9]Wang et al. 2026. At this point, the evidence for curved geometric structure inside neural networks is abundant and undeniable[10]Kozlowski et al. 2018, Chung et al. 2018, Saxe et al. 2019, Cohen et al. 2020, Chung and Abbott 2021, Abduo et al. 2021, Black et al. 2022, Park et al. 2024, Csordas et al. 2024, Diego-Simon et al. 2024, Gorton 2024, Marchetti et al. 2024, Bethune et al. 2025, Dooms and Gauderis 2025, Li et al. 2025a, Li et al. 2025b, Bigelow et al. 2025, Costa et al. 2025, Park et al. 2025, Pearce et al. 2025, Fel et al. 2025b, Lubana et al. 2025, Marchetti et al. 2026, Hindupur et al. 2025, Sun et al. 2025, Zhao et al. 2025, Yocum et al. 2025, Noroozizadeh et al. 2025, Sun et al. 2026, Shafran et al. 2026, Sofroniew et al. 2026, Shai et al. 2026, Liu et al. 2026, Luo et al. 2026, Sarfati et al. 2026, You et al. 2026, Hosseini et al. 2026, Dhimoïla et al. 2026, Wollschläger et al. 2026.
We believe this "neural geometry" is a crucial frontier in understanding, improving, and controlling models. If we understand how a model carves up and represents the world conceptually (i.e., its ontology), this will unlock a far deeper understanding of both its algorithms that operate over that ontology and the intelligent behaviors produced by those algorithms. We thus need new methods to gain that understanding; this series of posts details our early efforts to develop them, building upon – and alongside – numerous related efforts from others.[11]Saxe et al. 2019, Engels et al. 2024, Csordas et al. 2024, Modell et al. 2025, Gurnee et al. 2025, Fel et al. 2025a, Bigelow et al. 2025, Lubana et al. 2025, Kantamneni and Tegmark 2025, Karkada et al. 2026, Shafran et al. 2026
While we are deeply driven by curiosity about these questions in their own right, we also know that, historically speaking, the pursuit of fundamental scientific knowledge yields great practical utility. More concretely, we see clear and impactful applications of interpretability opening up—extracting scientific knowledge from foundation models,[12]Lu et al. 2026, Simon & Zou 2025, Brixi et al. 2026, Wang et al. 2026 and intentional design of better, safer models[13]Geiger et al. 2022, Wu et al. 2024, Wu et al. 2025, Yin et al. 2024, Chen et al. 2025, Prasad et al. 2026, Qwen Team 2026—and believe neural geometry can unlock the holistic understanding and fine-grained, robust control needed to power them.
Contents
A simple example of how neural geometry unlocks control
To give a peek into the inner world of a neural network, let's start with a simple example where we simulate data grounded in the laws of physics.
We start by training a simple image-action model on the classic RL environment 'mountain car', where the goal is to get a car in a valley to the top of a hill.[14]The aim is to drive a car to the top of the right mountain, but to do so it must first go up the left mountain to gain momentum. We ignore this objective for the purpose of our image-action model, which is trained on random action sequences. The model is trained to predict the next frame given the current state (the car's position and momentum) and a random input action (whether to accelerate left or right). The trained image-action model is a world model of the mountain car that is optimized to predict future states of this simulated physical system.
To reveal how the image encoder represents the position of the car, the plot above visualizes the embedding vectors (colored dots) from images with the car at different positions. The embedding vectors form an obvious string-like structure, where nearby positions along the string correspond to images with the car in nearby positions. The natural hypothesis is that this structure is how the model represents the position of the car.
To test this hypothesis, we perform "brain surgery" on the model to see if changing the position on the piece of string causes the predicted image to change the position of the car. First, we fit a one-dimensional manifold (a smooth curve) to describe the piece of string. Then, we intervene on the hidden activations to "steer" the representation along the manifold. The result validates our hypothesis; the car moves smoothly up and down the hill!
The more typical way to steer representations is to create a linear steering vector by taking differences in activations between contrasting pairs[15]Bau et al. 2019, Antverg & Belinkov 2021, Subramani et al. 2022, Marks & Tegmark 2023, Turner et al. 2024, Panickssery et al. 2024, Li et al. 2024. For example, to create a steering vector that represents truthfulness, we might average the embeddings from several true statements and subtract the embeddings from several similar-but-false statements. Linear models[17]The term "linear" is ambiguous and admits several principled definitions, some of which allow curved geometry. In this post, we use "linear" to refer to models of neural network representations that posit that concepts are represented as directions in activation space, and that the intensity of the concept is the magnitude in that direction. are a popular and surprisingly powerful approach[16]Smolensky 1986, Mikolov et al. 2013, Arora et al. 2016, Elhage et al. 2022, Park et al. 2024, Costa et al. 2025, Zheng et al. 2025! If the underlying geometry of truthfulness is linear, these steering vectors will work robustly; however, if it's more complex, then they will fail — either having no effect or making the model incoherent.
We can see a clear example of incoherence in our mountain car example: taking a linear path between positions crosses through states where the model's output becomes garbled — there seem to be large 'voids' in activation space that the model can't handle. Some of these linear paths actually intersect with a different valid activation, leading to the car teleporting to the corresponding location!
This simple example gives us a concrete glimpse of our point from the beginning of this post: neural networks often do not represent the world as a set of clean, linear directions. Even when a model has learned a scalar concept like position, that concept may live on a curved manifold rather than along a straight line in activation space. By following the geometry, we can intervene in ways that are precise and effective; by ignoring it, we risk pushing the model into unnatural and incoherent states. To understand and control neural networks, we need tools that respect the shape of their internal representations.
For more on steering along lines vs. manifolds, see the next post in the neural geometry series.
Representation, computation, and behavior
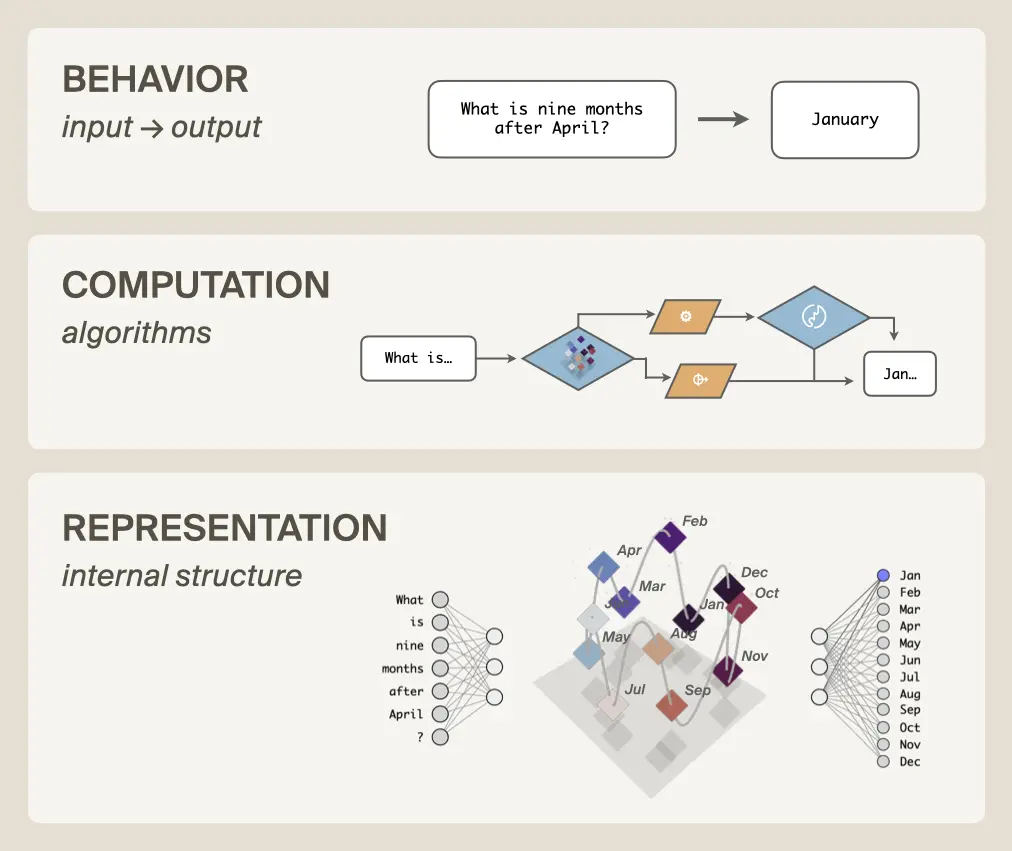
The power of neural geometry lies in its ability to help us precisely understand and manipulate three levels of structure in neural networks: representations, computations, and behavior.
Computation consumes and produces representations: data structures (stacks, lookup tables, etc.) represent information, and operators (push, pop, read, write, etc.) compute new data structures from the old. Therefore, we cannot fully understand computation without understanding representation. Imagine trying to figure out how a laptop sorts a list of numbers without knowing what bits are! You could make progress, but complete knowledge would be fundamentally out of reach.
We have made progress in understanding neural network computation[19]Giulianelli et al. 2018, Bau et al. 2019, Besserve et al. 2019, Vig et al. 2020, Geiger et al. 2020, Geiger et al. 2024, Geiger et al. 2025a, Geiger et al. 2025b, Finlayson et al. 2021, Ravfogel et al. 2020, Ravfogel et al. 2022, Elazar et al. 2021, Belrose et al. 2023, Cammarata et al. 2020, Elhage et al. 2021, Olsson et al. 2022, Chan et al. 2022, Davies et al. 2023, Stolfo et al. 2023, Wang et al. 2023, Conmy et al. 2023, Hanna et al. 2023, Nanda et al. 2023, Meng et al. 2022, Meng et al. 2023, Prakash et al. 2024, Merullo et al. 2024, Mueller et al. 2024, Wu et al. 2023, Arora et al. 2024, Huang et al. 2024, Kallini et al. 2024, Csordas et al. 2024, Feng et al. 2024, Braun et al. 2025, Bushnaq et al. 2025, Mueller et al. 2025, Prakash et al. 2025, Gur Arieh et al. 2025, Rodriguez et al. 2025, Boguraev et al. 2025, Huang et al. 2025, Minder et al. 2025, Grant et al. 2025, Sutter et al. 2025, but geometric structures are the data structures of neural networks and therefore necessary to fill out the picture. Only together can the two halves of representation and computation illuminate the intelligent behaviors of neural networks.
If we fully understood both representation and computation, then we could know exactly when models will fail, debug them if they do, evaluate and audit them with confidence, reshape their training, and generally build them with less mystery and more engineering. Understanding neural geometry is on the critical path to this ambitious vision.
Where does neural geometry come from?
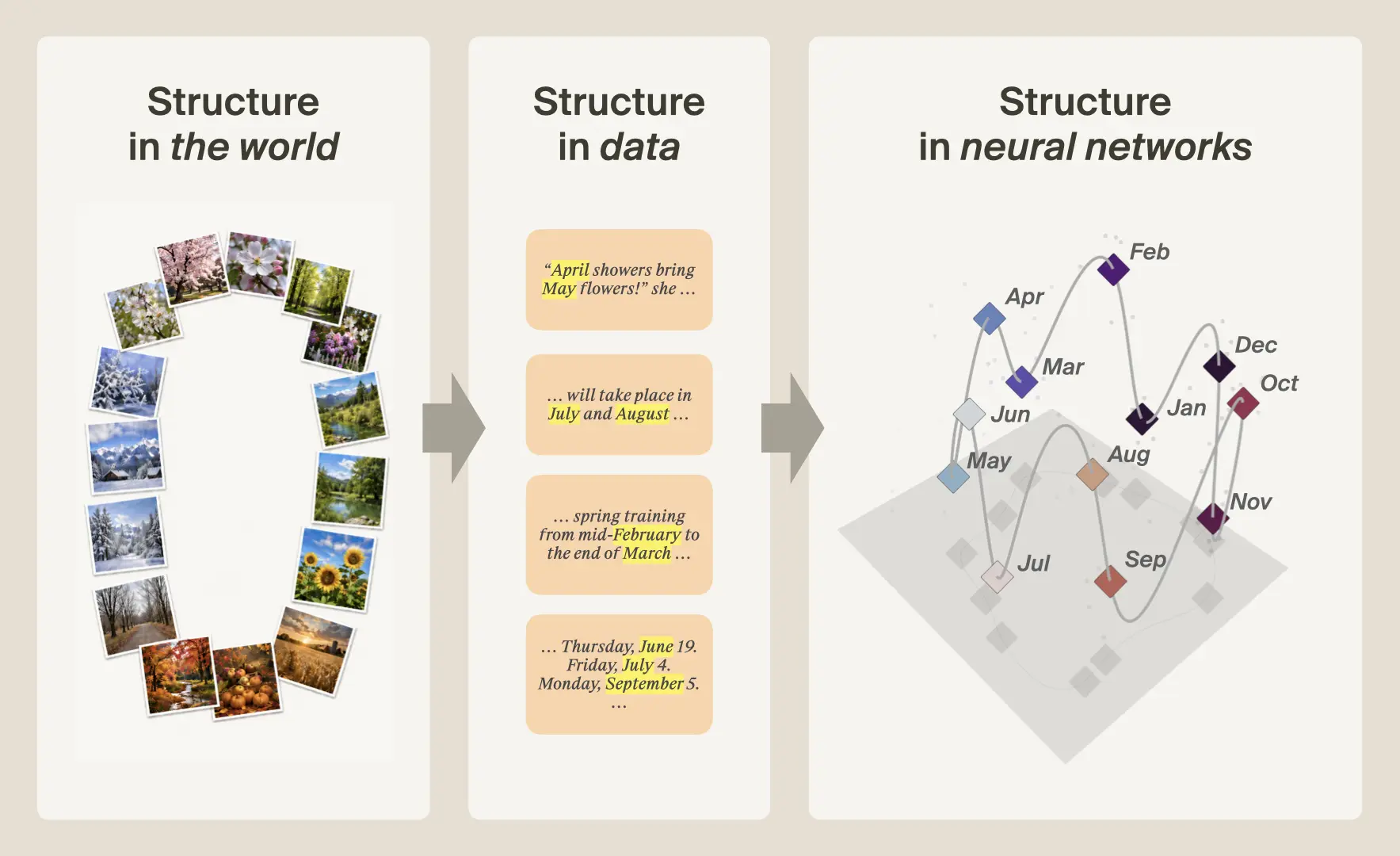
How does all this conceptual structure end up inside of neural networks?
The datasets used to train neural networks come from the world. Whether it's Reddit posts or a simulation of a car rolling down a hill, all data is downstream of our heavily structured reality. Neural networks are trained to model massive amounts of such data using a large, but finite, set of parameters. This optimization pressure forces the network to develop an inner world with a panoply of beautiful geometries that recapitulates the structure of the outer world. We cannot understand neural networks without understanding this process.[20]Merullo et al. 2025, Kakada et al. 2026, Prieto et al. 2026
Take the months of the year: in the world, months form a cycle, where January is near February and December, but far from June and July. That structure leaves statistical traces in text: nearby months tend to appear in similar contexts. During training, a language model is optimized to capture these regularities efficiently and thus the model's internal representations recapitulate the geometry of the underlying concept—in this case, arranging months in a cyclic structure.[21]Kakada et al. 2026, Prieto et al. 2026 Neural network computations are performed over such representations, ultimately producing the output behavior incentivized by training.
What about sparse autoencoders?
In the introduction to this piece, we gave several examples of geometric structure that emerge simply from training neural networks on natural language or images. In fact, the banner below the title shows manifolds from real language models that we've been using as test cases for an unsupervised pipeline, which we'll detail in forthcoming work.
The figure above was discovered using this unsupervised pipeline. Not only can we find structure in activation space (this manifold is populated with similar sounding rhyming words, e.g., fire and higher or near and dear), but this structure gives us a much cleaner picture of what's going on compared to the popular approach of using sparse autoencoders (SAEs)[22]Cunningham et al. 2023, Bricken et al. 2023, Gao et al. 2024, Lieberum et al. 2024, Menon et al. 2024, Fel et al. 2025.
Listed below are the SAE features (directions in activation space) that reconstruct the manifold. Automated interpretability labels[23]Bills et al. 2023, Huang et al. 2023, Choi et al. 2024, Gur-Arieh et al. 2025 of these SAE features identify only properties local to a point on the curve, which misses out on the underlying meaning of the manifold: words' phonological endings. That is, SAE features tend to "shatter" manifolds into many small and apparently-unrelated pieces, obscuring the overarching semantic structure that becomes clear when the manifold is viewed as a whole. We'll discuss this phenomenon — and how you can actually reconstruct manifolds from SAE features — in a future post of this series.
SAE FEATURES ON SLANT RHYME MANIFOLD
2478 : Words beginning with "Hor"
3596 : The word "correlation" and closely related statistical correlation terms
4583 : Words related to absorption/absorbance (absorb, absorption, absorbance, absorbent)
4596 : The token "Horde," especially in gaming or fantasy contexts
4806 : Words beginning with or containing the prefix "Port"
5316 : Human evolutionary history, especially ancestors, hunter-gatherers, and brain/body evolution
6440 : Words beginning with "import-" (important, importantly, importance, import, imported)
7471 : Legal opinion party labels like "Petitioner," "Appellant," or "Plaintiff" at sentence start
9514 : Words and names beginning with "Sor-"
10637 : Occurrences of the word "Corporate" in titles, headings, and organization names
12145 : Words beginning with the prefix "morph" (e.g. morphology, morphogenesis, morphing)
12714 : Token 'Nor' starting words, especially names and Norwegian/Norway terms
17398 : Tokens starting with "Mor" (e.g. names/words like Morris, Morocco, morality)
20283 : Words or names containing the substring "or," especially uncommon proper nouns
21241 : Boundaries between adjacent XML/HTML tags, especially closing container tags
22084 : Tokens starting with "Por"/"por", especially at the beginning of words
23104 : Tokens containing or beginning with "Horn" (e.g., Hornby, Hornets, Hornady, Hornblower)
23118 : Geometry descriptions involving triangle sides and right triangles
24140 : Proper names and places containing the syllable "tor" or "kor"
25233 : Scientific paper sentences where "we" introduces an experiment or investigation
28555 : Word-initial token fragment "Cor" in names and words
31648 : Words or names beginning with "Marg"
31747 : Tokens starting with "Dor" in names, places, and wordsAs the saying goes: all models are wrong, but some are useful. SAEs are valuable tools despite their limitations, particularly in their ability to break down a model into features at scale in an unsupervised way. But in order to more deeply and precisely understand and control neural networks, we'll need new methods — supervised and unsupervised — that respect neural geometry.[24]Engels et al. 2024, Lubana et al. 2025, Fel et al. 2025, Costa et al. 2025, Hindupur et al. 2025, Csordás et al. 2025, Kantamneni and Tegmark 2025, Muchane et al. 2025, Shafran et al. 2026
Conclusion
Neural networks have structured inner worlds with geometry that reflects the structure of reality. By developing theories and methods that respect neural geometry, we will unlock deeper interpretability, more reliable control, and safer, better AI.
Many have claimed that understanding the "black box" internals of neural networks seems impossible. We believe that developing this understanding is more than just possible: it is the greatest scientific challenge, and opportunity, of today.
While developing the theory of evolution, Darwin remarked: "My mind seems to have become a kind of machine for grinding general laws out of large collections of facts". Previously we simply didn't have a large enough collection of facts, nor the ability to collect them. With increasingly capable research agents, armed with better tools rooted in neural geometry, we will soon have a way to collect the right empirical data at scale—and can turn our minds to grinding out the general laws of thought.