Can SAEs Capture Neural Geometry?
AKA, how to use straight lines to capture curved geometry in neural networks

Curved geometry in neural representations is abundant and essential for understanding and controlling neural networks – but straight lines are much easier to work with.
Can we use lines to capture curved neural geometry?
Yes—but it's complicated. We are reminded of the old proverb in which blind men encounter an elephant for the first time. Each touches a different part—the trunk, the tusk, the leg—and each comes to a different conclusion about the elephant: the man touching the trunk says an elephant is like a snake, the one touching the leg says it's like a tree, and so on. Similarly, a single line can only give us a partial view of curved geometric structure, and consequently an incomplete understanding of the bigger picture. As with the elephant, the full meaning emerges only when the parts are understood as a whole.
In this post, we examine how the directions learned by sparse autoencoders (SAEs) relate to neural geometry, uncovering three different ways that lines can represent curved manifolds. Then, we leverage our understanding to develop an unsupervised pipeline for uncovering geometric structure in neural representations.
If we can automatically surface neural geometry, we can begin to understand neural networks at scale, on their own terms – by using the same internal geometry that they do. That in turn will enable deeper understanding and finer-grained, more robust control of neural networks.
Sparse autoencoders: missing the bigger picture
Sparse autoencoders (SAEs)[1]Cunningham et al. 2023
Bricken et al. 2023
Gao et al. 2024
Lieberum et al. 2024
Costa et al. 2025
Hindupur et al. 2025
Fel et al. 2025
See the following for a non-technical introduction. are a popular method in interpretability for decomposing neural representations using many different directions in activation space. These directions can be used to map out the inner world of a neural network; activations are expressed as a linear combination (weighted sum) of directions.
Interpretability researchers initially hoped that each direction, or feature, would be a single concept, and that the magnitude in that direction would correspond to something like intensity or confidence. While we now know that straight lines are not the universal "atoms" of neural cognition (see demos and citations from our main post), SAE features can still give us a window into more complex geometric structure.
Like the proverbial blind men and the elephant, no individual SAE feature can "see" the entirety of a curved manifold. But taken together, we can use the observations of a group of SAE features to reconstruct such a manifold.
Three ways SAE features can represent manifolds
We trained a sparse autoencoder on synthetic data that contained a mixture of geometric structures, including donuts, spheres, Möbius strips, and more. We found that as we change the number of directions used to reconstruct a representation, SAEs can recover geometric structures in three distinct ways:
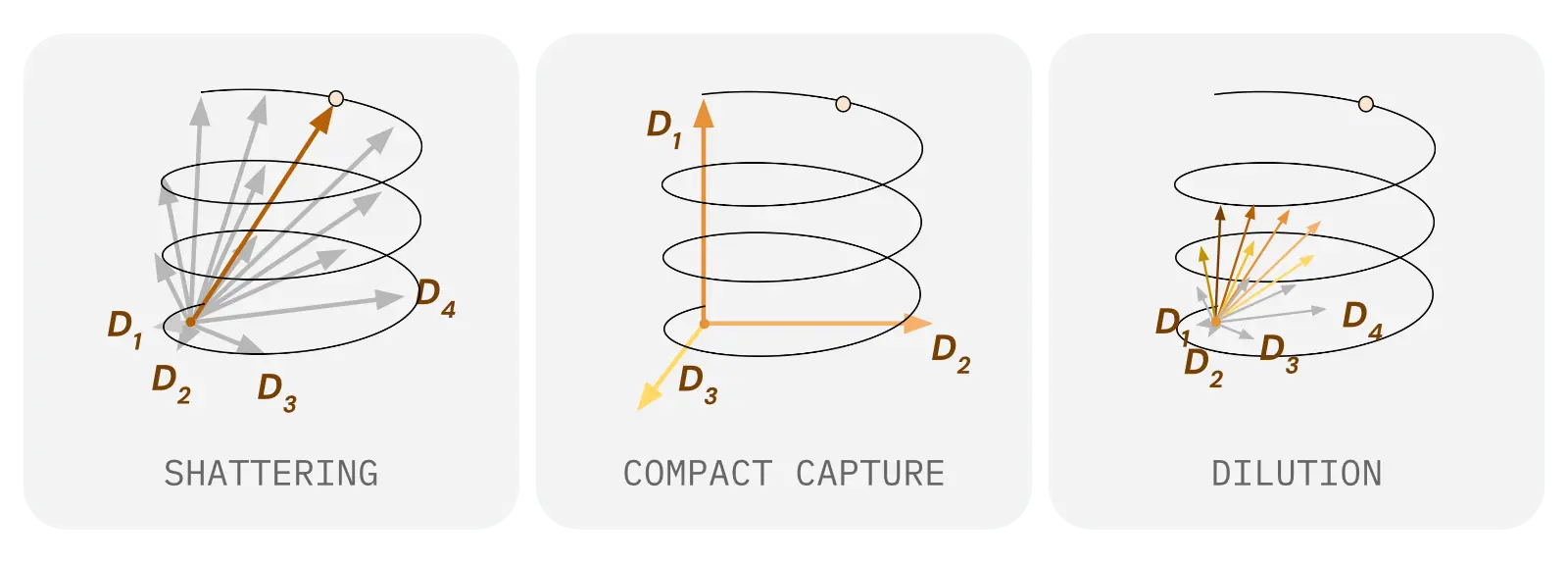
Shattering. Every point on a manifold is separately represented with a unique feature. These features "tile" the curved structure by each pointing to a single spot on it.
Compact capture. All the points on a manifold are jointly represented with a small set of shared features. The SAE features act as a coordinate system for the manifold, though not the most natural one (since they are straight lines, and the structure is a curved surface).
Dilution. Points on a manifold are represented by a moderate number of features that are partially shared between points. This is conceptually in between shattering and compact capture.
When we train SAEs on actual neural network representations, we observe dilution. Directions correspond to regions on the geometric structure with different sizes and locations. Consider the examples below, of real SAE features and manifolds:
Each of the individual SAE features cover different parts of the manifold. For example, consider the temperature manifold. The feature labeled "Cold weather and its effects" fires at one end, while the feature labeled "Extreme heat and its effects on activities and environments" fires at the other end.[2]Bills et al. 2023
Huang et al. 2023
Choi et al. 2024
Gur-Arieh et al. 2025
Dilution helps explain why SAEs can feel simultaneously illuminating and unsatisfying. A single SAE direction may pick out a meaningful local region of a manifold, but the manifold itself is distributed across many such directions. Looking at those directions one-by-one is like trying to understand the elephant by speaking with each of the blind men: each label may be locally accurate, but the global structure is missing.
An unsupervised pipeline for discovering concept manifolds
If individual SAE features only reveal local pieces of a manifold, then we should stop interpreting them in isolation and instead search for groups of features that collectively recover the full structure. We turn this idea into an unsupervised pipeline.
We use SAEs to reconstruct many different internal representations and collect the firing patterns (i.e., which SAE features were used to reconstruct which activations). Then, we cluster the features based on statistical dependencies in these firing patterns.
For each cluster of features, we ask what geometry is captured by the space that those features span. Each straight line covers a fragment, and together a cluster reveals the overall geometry.
The examples below show a few manifolds that our pipeline found in Llama 3.1 8B:
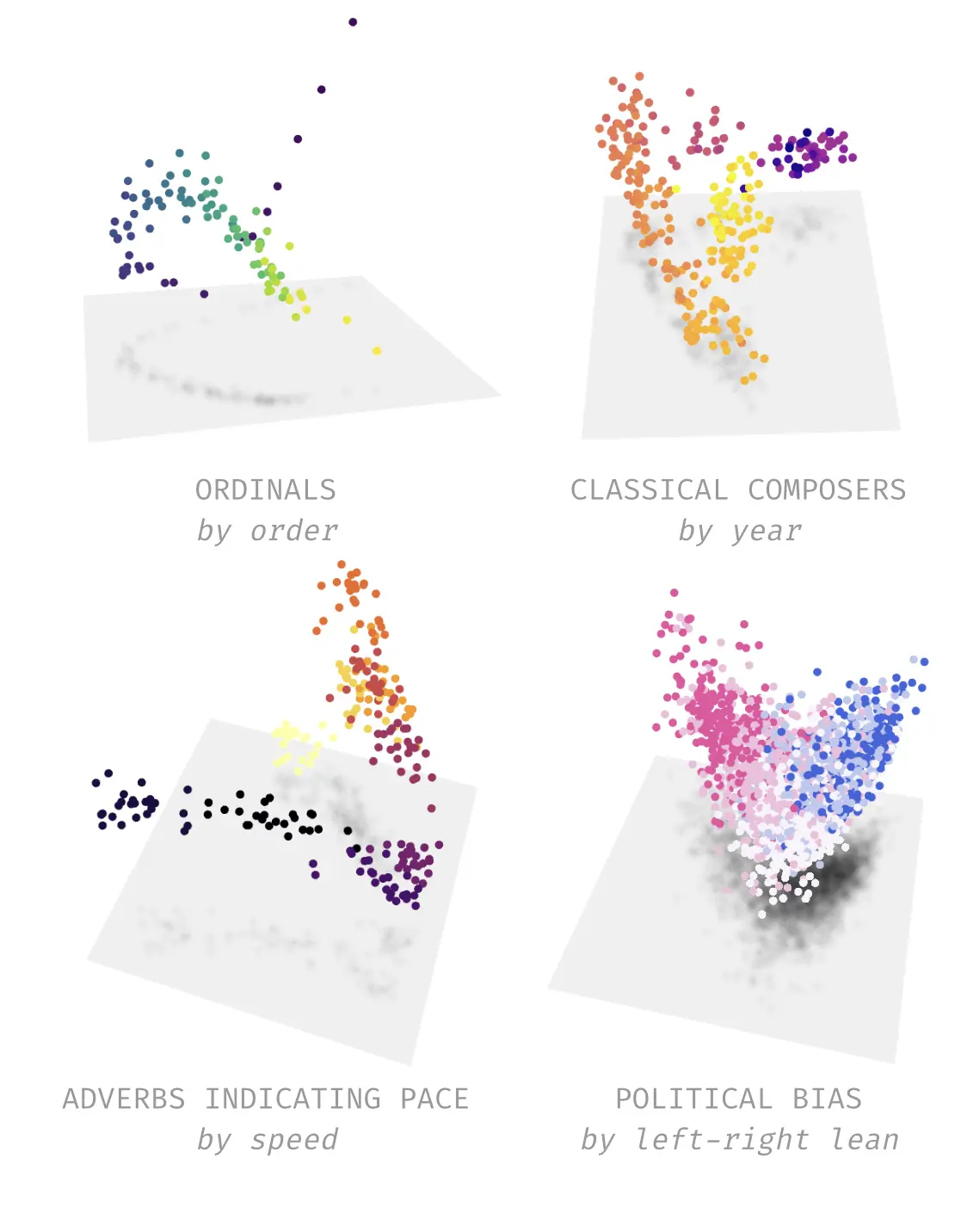

While we have had clear success, we don't believe that post-hoc processing SAE directions is the most efficient pipeline. We have new architectures in the works that are tailored to the task of unsupervised manifold discovery.
Conclusion: Towards automatically understanding manifolds
By moving from isolated directions to multidimensional manifolds, we can turn local fragments into a holistic view of neural geometry. That said, methods that use directions as features, such as SAEs, remain a useful tool for decomposing activations, so long as we remain aware of their limitations.
Additionally, an unsupervised pipeline for surfacing manifolds is only half the battle; representation geometry provides the data structures, but we also need to know how internal operations (computations) over geometric structure generate the intelligent behaviors we want to control and design. (We are developing specialized research agents for automatically tackling this problem at scale!) Only by understanding these together will we be able to achieve the broader vision of interpretability: a holistic, mechanistic understanding of neural networks.
Read the full paper →