Intro
Modern AI models have become remarkably capable at solving complex problems by thinking step-by-step before arriving at an answer, referred to as chain-of-thought (CoT) reasoning. Training these models with reinforcement learning (RL) has led to longer, more elaborate reasoning traces that seem monitorable: we can simply read what the model is thinking.
However, prior work has indicated that this chain-of-thought is not always faithful to the model's internal computations, with models producing plausible rationales that don't reflect the true causes of their decisions (Arcuschin et al., 2025Chain-of-thought reasoning in the wild is not always faithful [link]
Arcuschin et al., 2025.; Korbak et al., 2025Chain of thought monitorability: A new and fragile opportunity for ai safety [link]
Korbak et al., 2025.; Lanham et al., 2023Measuring faithfulness in chain-of-thought reasoning [link]
Lanham et al., 2023.; Turpin et al., 2023Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting [link]
Turpin et al., 2023.). Recent work has also shown that correctness and uncertainty can be decoded from model activations during reasoning (Zhang et al., 2025Reasoning Models Know When They're Right: Probing Hidden States for Self-Verification [link]
Zhang et al., 2025.; Zur et al., 2025Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics [link]
Zur et al., 2025.). Given that activations contain these rich signals, we can decode relevant information that hasn't been verbalized explicitly in CoT.
We build on these findings to track how a model's internal beliefs about the final answer evolve throughout reasoning, and compare this to what the model actually communicates in its CoT. A mismatch between the two is performative reasoning: the model's written CoT reads like genuine deliberation, but its activations tell a different story (Palod et al., 2025Performative Thinking? The Brittle Correlation Between CoT Length and Problem Complexity [link]
Palod et al., 2025.). We find that this happens often, especially early in reasoning on easier tasks. However, key verbalized inflection points (“Wait” or “Aha” moments) do seem to occur in genuinely uncertain responses. We further show that probing for the final answer throughout CoT can be used for confidence-based early exit to avoid generating unnecessary tokens.
Methods
We study performative reasoning in the responses of two large open-weight models (DeepSeek-R1-0528-671B and GPT-OSS-120B) and the DeepSeek-R1 distilled model family on two popular multiple-choice benchmarks (MMLU-Redux and GPQA-Diamond). To study how a model's internal prediction changes over time both internally and in the CoT, we use three different methods to infer the model's final answer before it finishes reasoning.
- Probes: We train context-pooling probes (attention probes) on the model's internal activations to predict the model's final multiple-choice answer at any point during generation. This gives us a probability distribution over answer choices that evolves as the model reasons.
- Forced Answering: At an intermediate point in reasoning, we inject a prompt that forces the model to commit to a final answer immediately, bypassing the rest of its CoT. This tells us what the model would answer if made to answer right now.
- CoT Monitor: We provide the text up to an intermediate point in reasoning to another LLM and ask it to infer what final answer the original model is leaning towards based on the CoT. This captures what an external observer could infer about the model's belief.
By comparing these three methods, we can identify when a model's internal belief diverges from what it communicates in text. We define performativity as the difference in predicted final answer accuracy between CoT monitoring and probing/forced answering at a given token position.
We also use the CoT monitor to identify key verbalized inflection points in the reasoning trace where the model appears to change course, such as “Wait” and “Aha!”. By comparing these moments with our probe's confidence, we can test whether verbalized inflection points reflect genuine internal uncertainty or are just performative filler.
Finally, we use the probes described above to exit chains-of-thought early (i.e., when they become performative), and evaluate the resulting token savings and change in benchmark performance.
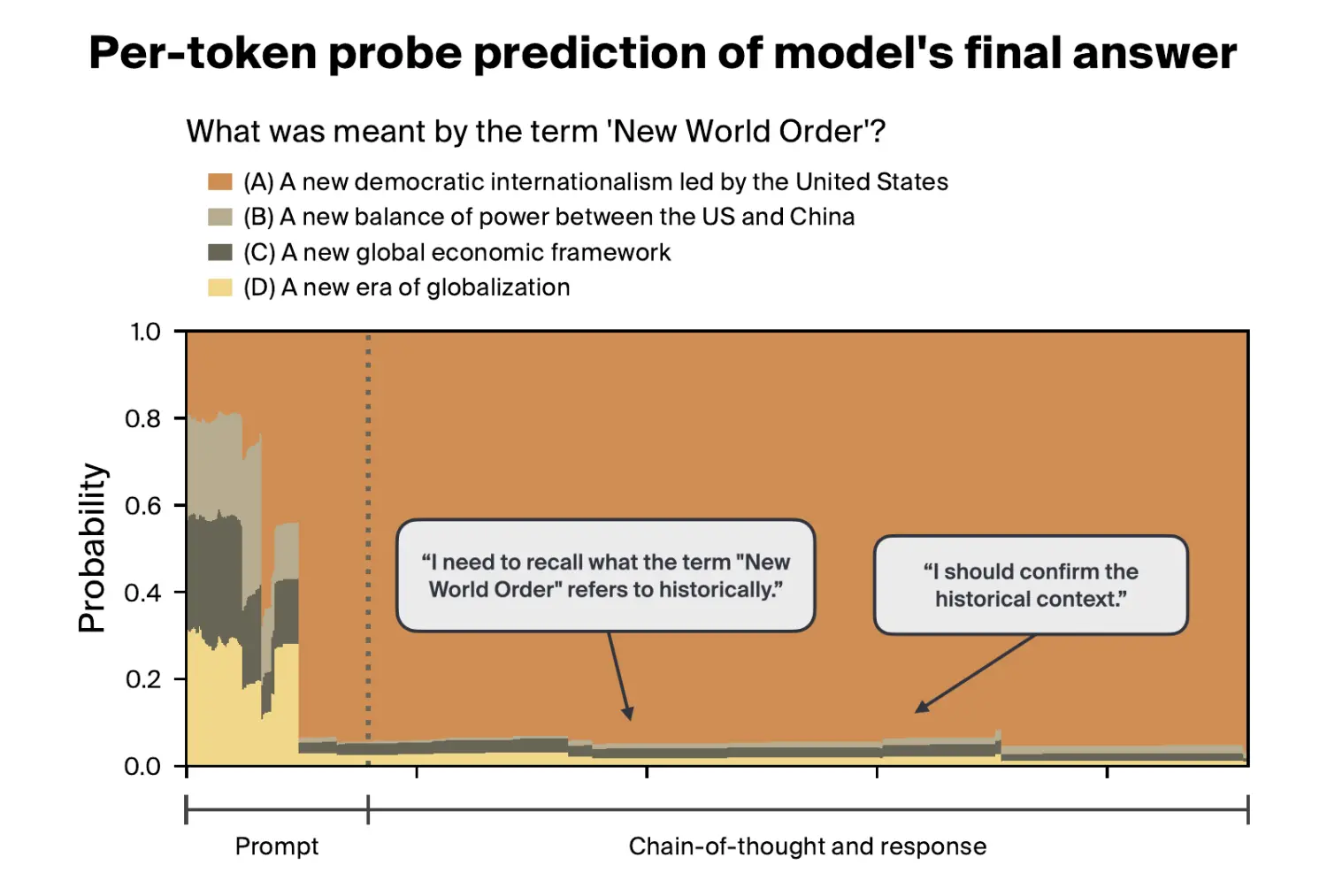
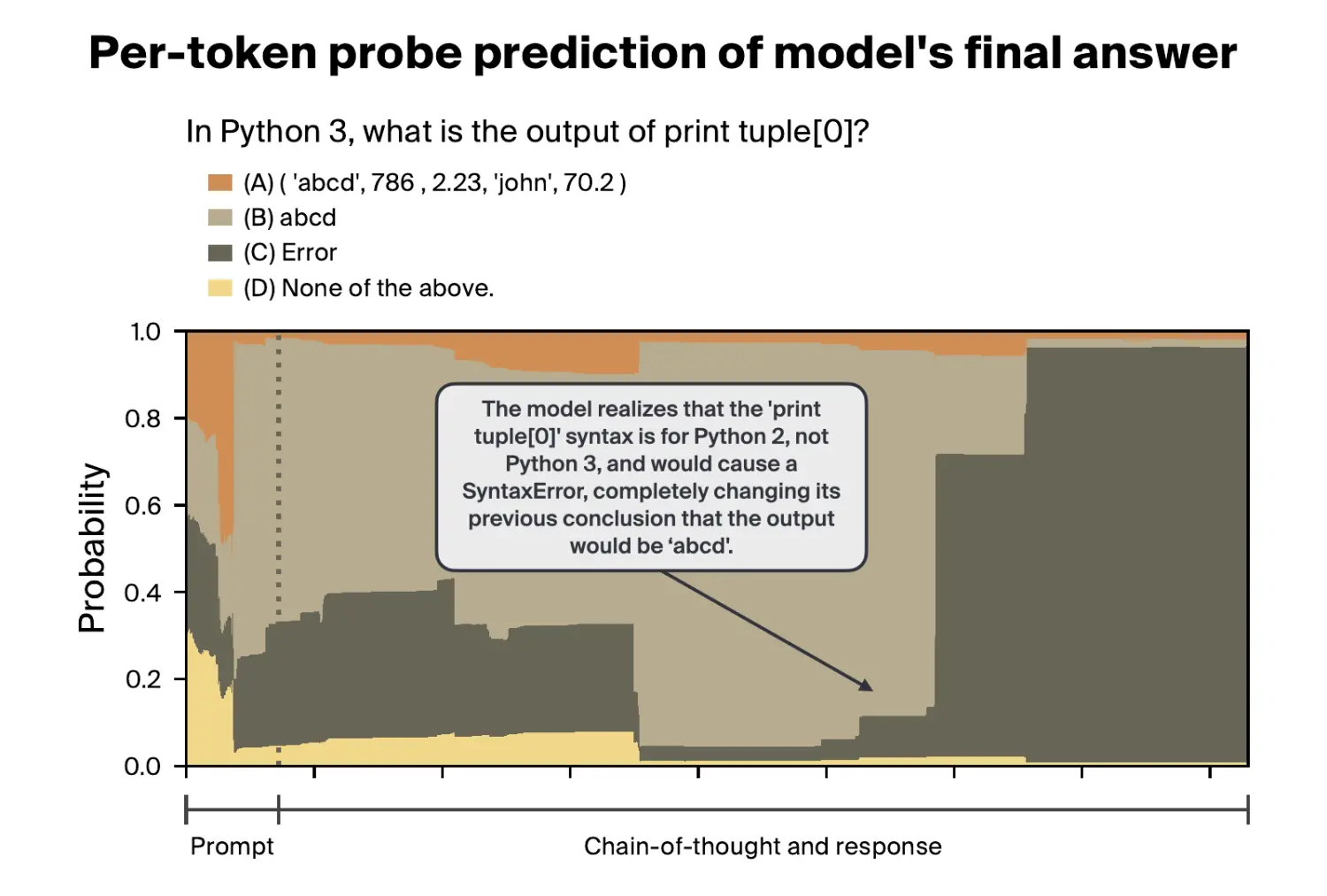
You can visit our Streamlit app to explore how answer probabilities change over layers and tokens for various prompts.
Results
Attention probes identify final answer information early in reasoning.
We evaluate our probes by first averaging their accuracy across all token positions for each question, then averaging across all questions from a held-out test set. Our best attention probes achieve 87.98% accuracy on MMLU, indicating that they can identify the final answer very early into reasoning.
We also evaluated single-token linear probes, finding that they don't perform better than 31.85% accuracy (i.e., not much better than the random baseline of 25%).
Easier tasks tend to have more performative reasoning.
On easier recall-based MMLU questions, probes and forced answering can often decode the model's final answer with well-above-chance accuracy from the very beginning of reasoning, while the CoT monitor lags behind. The model internally knows its final answer from the start, but hasn't revealed it yet.
On harder GPQA-Diamond questions requiring multi-step reasoning, all three methods start with low accuracy and improve gradually together, indicating that the written CoT is more faithfully tracking the model's evolving beliefs.
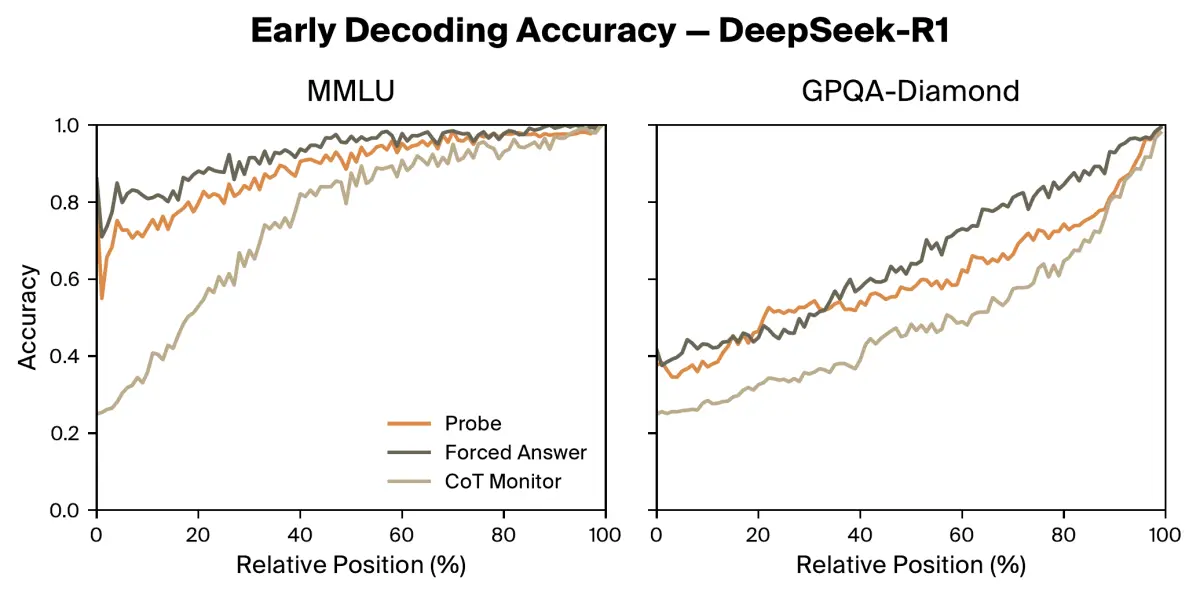
We see a similar trend across model sizes: larger models know their final answer earlier for MMLU questions, as the answers are likely already memorized or easily recallable, while smaller distilled models use more of their CoT to arrive at the answer. Relative difficulty appears to correlate with performativity: the same tasks are harder for these smaller models, resulting in more genuine CoT.
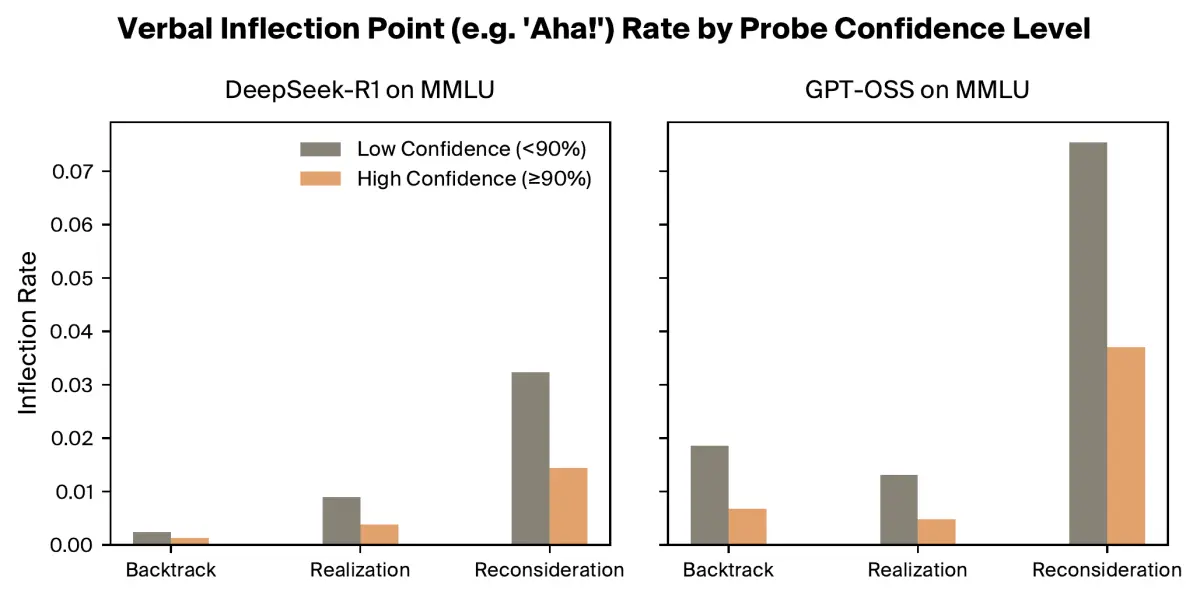
Inflection points reflect genuine uncertainty, but don't track belief shifts locally.
Highly confident responses (as determined by our probe) contain half as many verbalized inflections than less confident responses, suggesting that inflections correspond with genuine internal uncertainty. However, individual inflection points do not reliably coincide with shifts in probe confidence.
Probes enable early exit — eliminating superfluous reasoning tokens with minimal performance degradation.
We find that our probes are well-calibrated, allowing us to use their prediction as the answer directly during the middle of reasoning. For DeepSeek-R1, early exiting at 95% probe confidence saves 68% of tokens on MMLU and 33% on GPQA-Diamond while retaining over 95% of original accuracy. This gives us a knob to control the tradeoff between accuracy and token usage, enabling adaptive inference-time compute.
| Model | Dataset | Tokens Saved (%) | Accuracy (% of baseline) |
|---|---|---|---|
| DeepSeek-R1 | MMLU | 67.7% | 96.7% |
| DeepSeek-R1 | GPQA-Diamond | 33.4% | 100.8% |
| GPT-OSS | MMLU | 61.3% | 94.9% |
| GPT-OSS | GPQA-Diamond | 26.1% | 98.2% |
Takeaways
Our findings present a nuanced picture of faithfulness in reasoning LLMs: models genuinely reason through hard problems, but coast through easy ones while generating superfluous chain-of-thought. Meanwhile, key inflection points correspond with internal uncertainty at the response level, even if their precise timing within a response remains unclear. Probes can enable monitoring for such (un)faithfulness by using signals that aren't present in model outputs, with minimal inference overhead.
By calling some reasoning “performative”, we do not mean to ascribe deception to models, but to describe the mismatch between their externalized reasoning and apparent internal state. RL training incentivizes reasoning that leads to correct answers, so the resulting CoT only needs to be useful to the model. Meanwhile, chain-of-thought monitors are only as good as the chain-of-thought itself.
Interpretability methods can augment monitors by identifying relevant information internally that isn't reliably expressed externally. Understanding why this gap between internals and CoT exists, and building tools that narrow it, is key for ensuring that these systems are monitorable and aligned.
Furthermore, well-calibrated probes give us a knob to control the tradeoff between accuracy and token usage, enabling adaptive inference-time compute. If we want to optimize solely for expected accuracy, it may actually be rational for a model to continue reasoning even while it is confident in a final answer. However, when taking token costs into account, many use cases may benefit from saving large numbers of tokens at the expense of a small hit to accuracy.
Read the full paper for more details.
This work began as a SPAR fellowship project.