Introduction
The critical technologies of our time, from clean energy to advanced computing to space flight, all depend on the discovery of new materials. But progress in materials science has not kept pace with advances in fields like software or biology, and it takes decades to discover and manufacture new materials. The problem is that scientists can only do so many experiments and analyses, and have historically had to do them sequentially in slow feedback loops before even beginning to think about industry applications.
Radical AI is building a fully autonomous and intelligent approach to materials design, where AI models generate hypotheses, self-driving robotic labs execute experiments, and the entire stack learns and improves in a continuous closed loop that compresses decades of materials development into months.
A critical step in this process is finding candidate materials: given the universe of possible materials, which should we create and test? Goodfire partnered with Radical AI to improve this step in the process using interpretability tools. We were able to improve generation by giving a diffusion model a feedback loop from its own internals, resulting in ~30% more viable candidate materials in a target range.
Though our focus here is materials, self-correcting search is a general technique potentially applicable to any diffusion model, opening the door to similar gains in domains like protein design and drug discovery.
Background
Inverse design
The promise of generative materials modelling is true inverse design: starting with the properties needed for an application, then navigating the vast space of possible chemistries and structures in silico to directly propose the best options to be synthesized in the real world. One of the materials domains Radical AI has explored is unearthing new semiconductors. With a model that has learned the full distribution of stable materials — i.e. all chemistries and structures that are physically possible — we should be able to point it at a target property range, like a bandgap of 4–6 eV, and surface novel candidates. Rather than searching through known materials for ones that happen to fit, the model proposes new ones directly.
One way to approach the inverse design problem is with conditional generation: targeting the exploration of the search space to only surface candidates that have the desired physical or electrical properties. In the language of approximate inference, we have a cheap forward process – computing the property of a material – and we'd like to invert that process to sample from the distribution of materials with a given property.
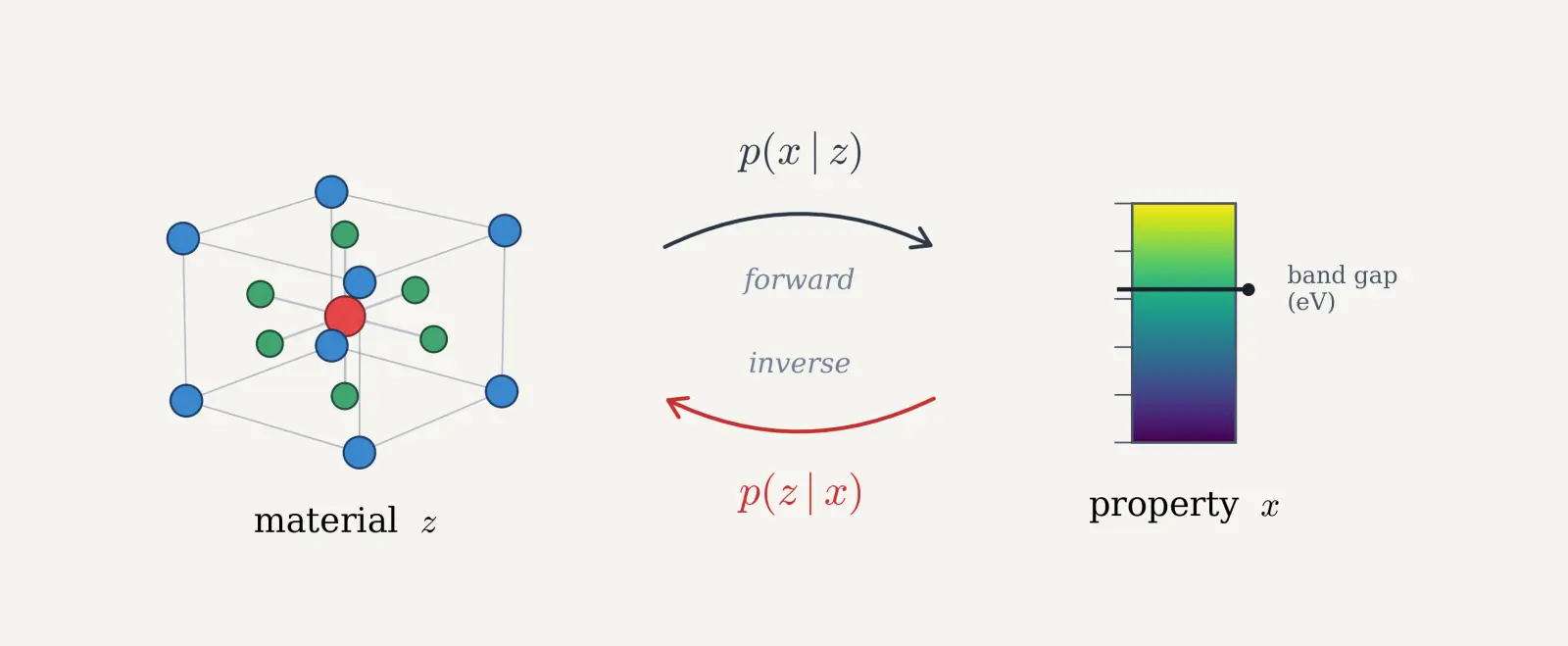
In this work, we set out to improve how consistently the model surfaced candidates that both have the desired properties (targeting) and are viable (Stable, Unique, and Novel, or SUN). SUN, a standard metric for materials viability, comprises three constraints:
- Stable: Can this material exist in the real world? The typical ground truth is Density Functional Theory (DFT), a quantum mechanical method that computes the energy of a material's atomic configuration. Materials with higher total energy are more likely to break down into simpler compounds. If a candidate material does not sit near the stable energy minimum, it is unlikely to be synthesizable in the real world. DFT is often approximated by ML methods.
- Unique: Is this material different from the rest of the candidates generated in the batch? We want to sample the full space of possible materials, not the same few materials.
- Novel: Did we already know about this material? We typically approximate this by checking whether the material was in the training data of the model.
There are tradeoffs between these constraints. A model that outputs the same stable, known material every time would have perfect stability, but no uniqueness or novelty. On the other hand, a model that outputs random materials would produce unique and novel materials that are unlikely to be stable.
Fine-tuning MatterGen
MatterGen is a generative materials model that generates candidate chemistries (which elements are used) and associated structures (how those atoms are placed in a crystal lattice). It is trained as a diffusion model, learning to denoise progressively from pure noise to a particular material.

Current methods fine-tune MatterGen to do conditional generation by injecting the desired property values directly into the model and then using the fine-tuned conditional model to steer the predictions of the original model. This gives us a single hyperparameter to tune, $\gamma$, which controls how much to weight the conditioning. Increasing gamma improves targeting, but at the cost of uniqueness; conditioning the model too strongly hurts the diversity of output, known in generative modelling literature as mode collapse.
The status quo targeting numbers are very low. Considering band gap, only 15% of MatterGen-generated samples achieve a band gap within the requested target range of 4–6 eV. That drops to 6.5% when only considering SUN materials.
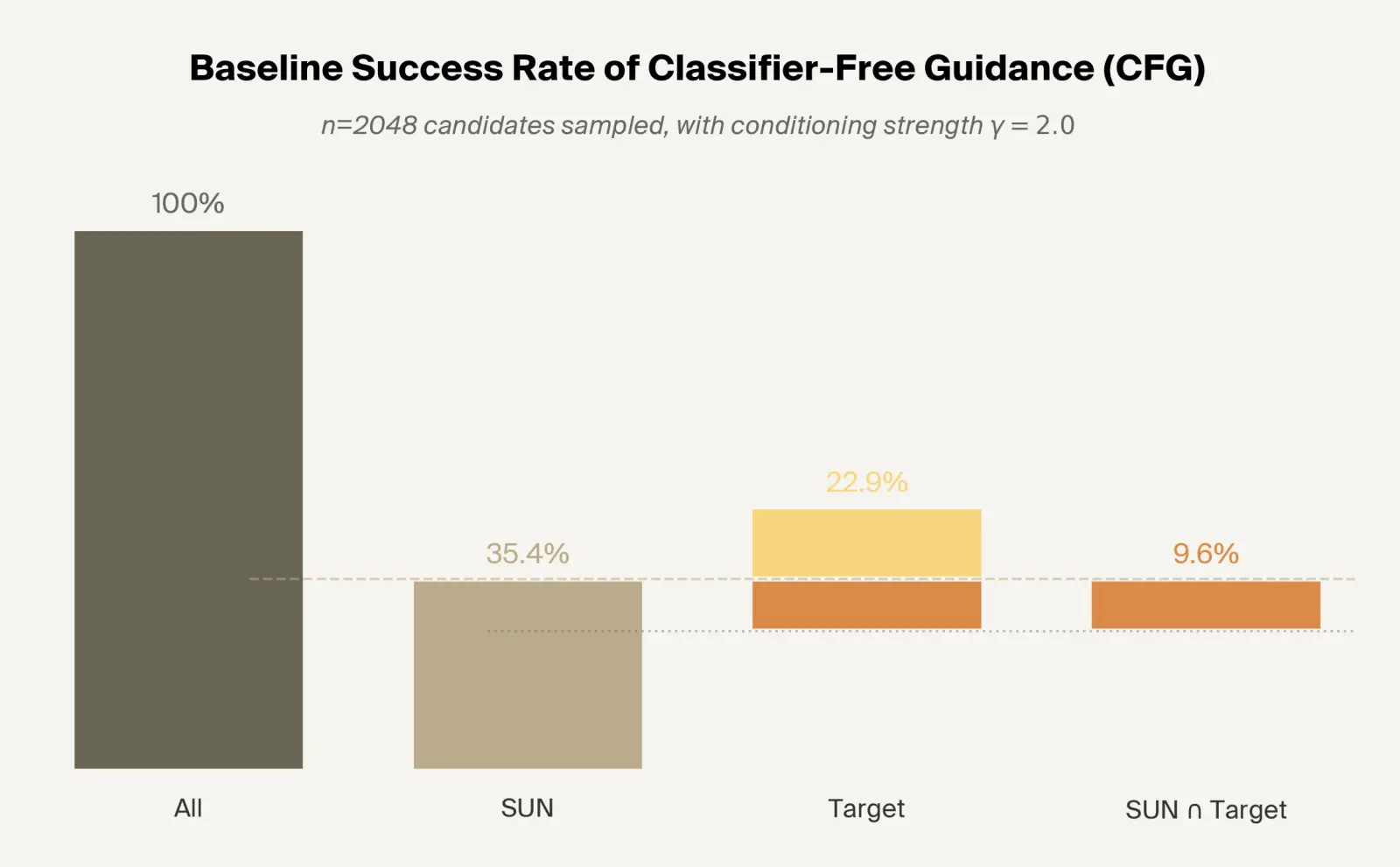
Current techniques allow for the model to generate based on its embedding structure, but not evaluate its generations. Using a probe, we extract the structure already within model embeddings and use it to correct the model during sampling, achieving better targeting at no cost to uniqueness.
Self-correcting search
Diffusion models augmented with classifier-free guidance are one way to do approximate inference: progressively denoising from pure noise to realistic sample. At each denoising step, the diffusion model takes a step towards a less noisy material, guided by a conditional model, eventually ending up with a realistic material.
Notably, in this process there is no correction or verification of each denoising step. The model moves in the direction it chooses, so if the model makes an error, there is no mechanism for it to recover. In our work, we take inspiration from approximate inference to do search, integrating feedback into the sampling process.
Self-correcting search gives the model a feedback loop derived from model internals. We train a probe to predict, based on the model's activations, what the property value of the final material will be. These predictions are used to accept or reject denoising steps — which we call proposals, in line with other MCMC-based methods of approximate inference. If the proposal has a better predicted band gap, we accept. Otherwise, we accept with a probability inversely proportional to how much worse it is. This sampling algorithm is called Metropolis-Adjusted Langevin Ascent (MALA).
Previous work (e.g. Kapur et al. 2024) has shown the effectiveness of using exact search metrics to provide diffusion models with an iterative feedback loop. Self-correcting search generalizes this to an approximate search metric computed from model internals (similar to Gruver et al. 2023), based on the idea that model representations can be richer and more informative than model outputs.
Results

Applying self-correcting search improves targeting without harming SUN scores, leading to an overall ~27% increase in successful candidates.
We applied self-correcting search to a MatterGen checkpoint finetuned for band gap-conditional generation. Using the same sampling parameters, we are able to increase targeting and novelty at minimal cost to stability, overall generating ~30% more SUN materials with band gaps in the target range.
We further find that self-correcting search dominates only using fine-tuned guidance over all conditioning strengths, pushing forward the frontier of band gap targeting and viability.
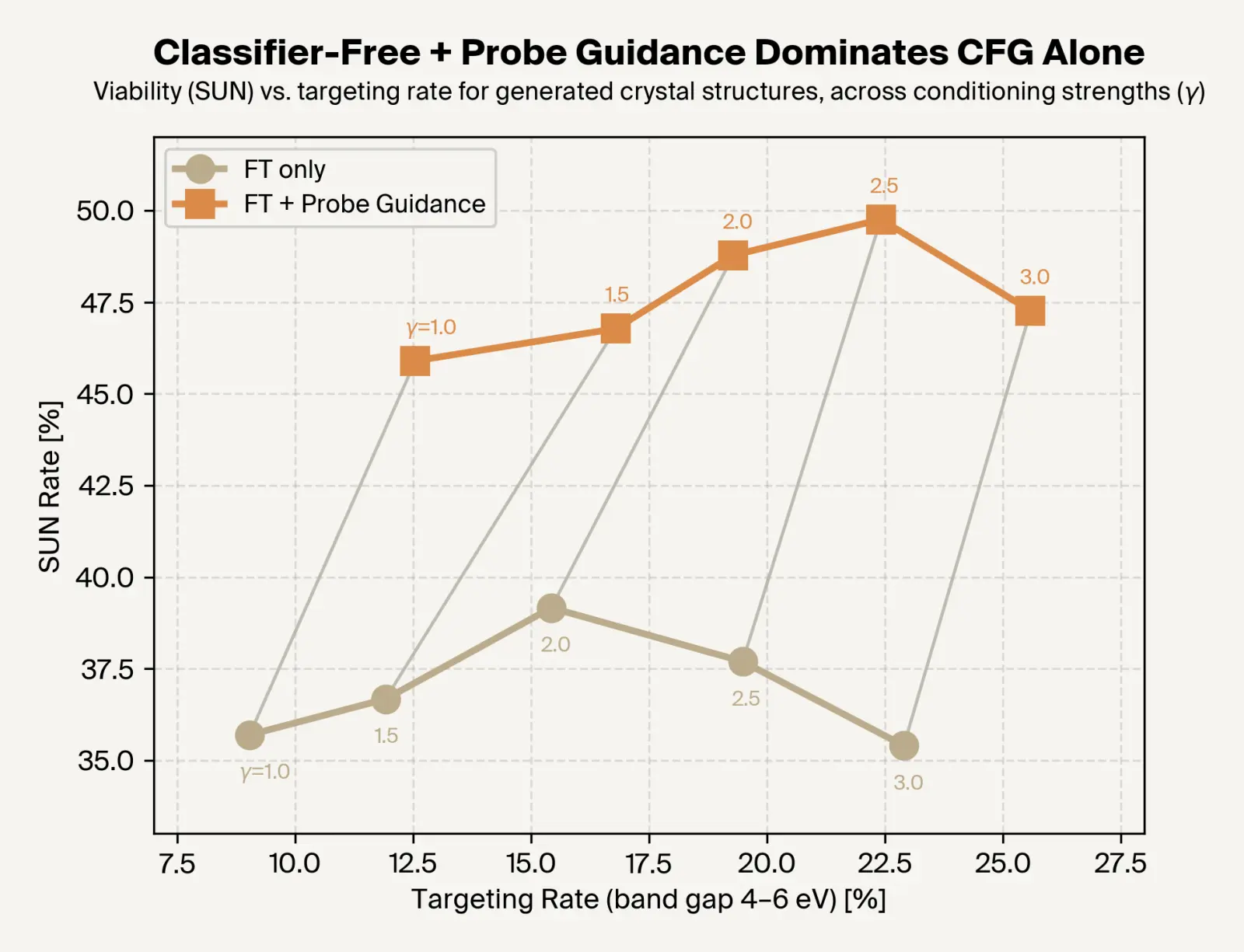
Overall, this means that using signals from model internals allows us to meaningfully improve the efficiency of conditional generation with MatterGen.
Discussion
These results demonstrate that self-correcting search is a flexible, low-downside way to steer diffusion models towards the properties we care about. Beyond materials science, it could unlock test-time steering for models trained for tasks like protein design, small molecule generation or de novo antibody design – anywhere diffusion models are used to explore large structured spaces.
Zooming out, the key insight behind self-correcting search is that models contain rich internal structures that often encode more information than model outputs – an insight we use across our work. We can use these structures as richer supervision for models, as RL rewards to reduce hallucinations in language models, or here as test-time feedback to enable the use of search.
As scientific models scale and improve, their representations will encode deeper and more meaningful information. Understanding and leveraging model internals will be crucial across domains as more and more science is done in silico, and self-correcting search is one way to harness that information. We're excited to continue such work to advance scientific abundance.