
Interpretability Infrastructure at Frontier Scale: Harvesting Activations from a Trillion-Parameter Model
At Goodfire, our mission is to move past the era of black boxes by advancing the science of interpretability: developing and applying techniques that let us see inside models, learn from them, and make them more reliable.
Executing on that mission means applying interpretability at the frontier, ensuring that our methods work with the AI systems actually being deployed in the world. These models are more challenging to work with than simpler 'model organisms' — they have more complex architectures (like mixture-of-experts layers), reason over many steps, make tool calls to interact with the world, and, perhaps most importantly of all: they are big.
When Anthropic published Towards Monosemanticity in 2023, they deliberately worked with a toy model — a single-layer transformer with 512 neurons — to develop foundational techniques. Today's frontier models exceed the trillion parameter threshold. Our mission therefore requires solving hard engineering problems in addition to research on new methods.
While we share a lot about our research, we’d also like to highlight the behind-the-scenes engineering work that complements it. This post shares one example of that work: building the infrastructure to scale core interpretability techniques to Kimi K2 Thinking, a trillion-parameter model, in a single overnight run.
We did this by forking an inference server, adding activation harvesting to a highly optimized inference engine while keeping the patch surface surgical. This work allowed us to harvest 3 billion activations overnight, letting us explore the underlying concepts in Kimi K2 Thinking’s latent space and enabling real-time, mid-chain-of-thought steering.
Contents
Background: A crash course on inference at scale Why use an inference server? Inference server optimizations (and why they complicate everything) Our approach: design considerations and implementation Controlling complexity Shaping SGLang for our workflow Results: What we built An efficient pipeline Steering a trillion-parameter brain Engineering is core to interpretability We’re hiringBackground: A crash course on inference at scale
Why use an inference server?
Sparse autoencoders (SAEs), a core tool of interpretability, are a method for decomposing a model's internal activations into interpretable features. SAEs learn to reconstruct the residual stream using a sparsely-activating set of directions, and those directions often correspond to human-understandable concepts.
Training a useful SAE requires a lot of data, and more data as models scale. SAEs are trained on activations extracted from the target model as it processes examples. Large models encode more concepts and finer distinctions, which means you need richer training data to capture that structure. For smaller models, useful SAEs can be trained on tens of millions of tokens. But for a model the size of Kimi K2 Thinking, we need billions. For an initial pass analyzing Kimi K2 Thinking, we needed to harvest single-layer activations for 3 billion tokens, which, once compressed, is ~33 TB on disk.
For comparison, 3B tokens is roughly half of English Wikipedia (~6.5B tokens).
At naive throughput (say, 100 tokens per second), harvesting activations on 3B tokens would take over a year of continuous GPU time. To make it practical to do interpretability work with a large frontier model, you need throughput in the tens of thousands of tokens per second.
We achieved this with inference servers, which provide highly optimized model runtimes to maximize GPU utilization in a distributed setting. SGLang and vLLM are two of the leading open-source inference servers, and both support the kind of large-scale distributed inference that trillion-parameter models require. We opted to work with SGLang because we judged we could make a more surgical fork.
Inference server optimizations (and why they complicate everything)
Inference servers like SGLang achieve their speed through optimizations that complicate activation harvesting. Alas, we cannot simply “hook the model and save the tensors.”
Continuous batching. Requests arrive asynchronously and get merged dynamically to keep GPUs busy. A "batch" during prefill isn't necessarily shaped like [batch_size, seq_len]. Instead, tokens from many sequences are concatenated into a flattened 1D tensor with shape [sum(seq_lens)]. Provenance (the source token/context for each activation) and postprocessing must be handled with care.
Chunked prefill. Long prompts are split into chunks. A single sequence can become several forward passes. This keeps memory bounded and scheduling smooth, but it means a single document's activations arrive across multiple captures with different metadata.
Tensor parallelism. Kimi K2 requires sharding across 8 GPUs. Each rank holds a slice of the weights and participates in collective operations. If you capture activations naively on every rank, you get partial representations that need to be gathered — or, if you capture after synchronization, duplicated data.
CUDA graphs. Inference servers often pre-record execution graphs for speed, especially during decode. But this poses difficulties for conditional capture hooks.
Prefill vs. Decode: A critical distinction for activation harvesting
For SAE training, we don't need to harvest the forward-pass activations while computing model completions. We can instead precompute rollouts and harvest the forward-pass activations over them, meaning we can focus entirely on prefill and skip decode.
This distinction matters because the two phases have fundamentally different performance characteristics, and the value of different optimizations varies by mode:
Prefill processes many tokens at once and parallelizes across sequence length. The model sees the whole prompt, computes attention across all positions (subject to causal masking), and produces activations shaped like [seq_len, d_model]. This is compute-bound and fast.
Decode generates one token at a time, autoregressively (i.e., each token depends on the previous ones). You can batch across sequences, but within a sequence, generation is inherently sequential. Activations are shaped like [batch, 1, d_model]. This is memory-bandwidth-bound and significantly slower per token.
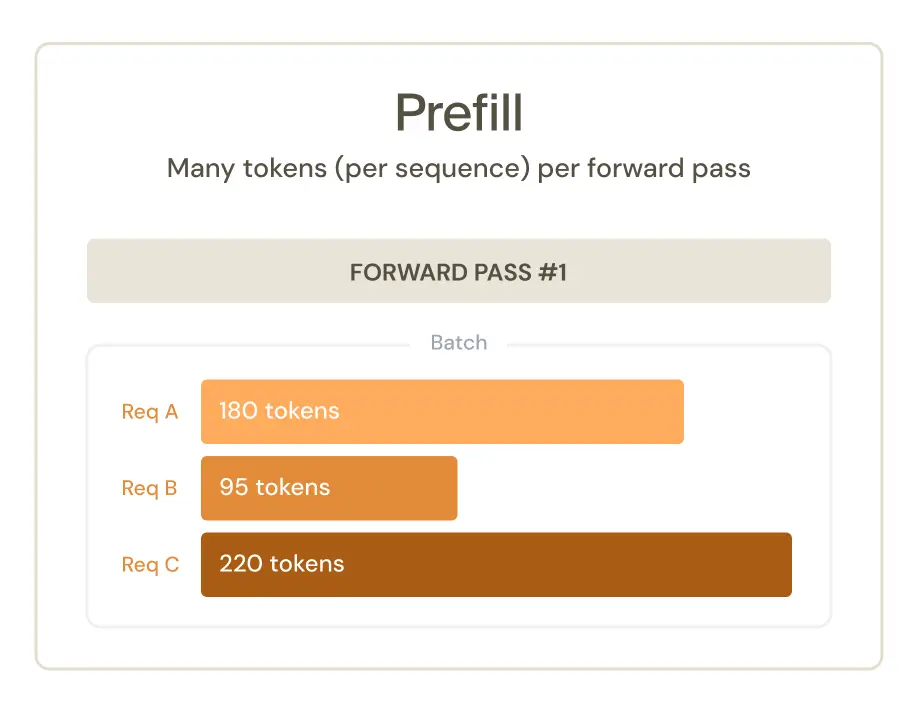
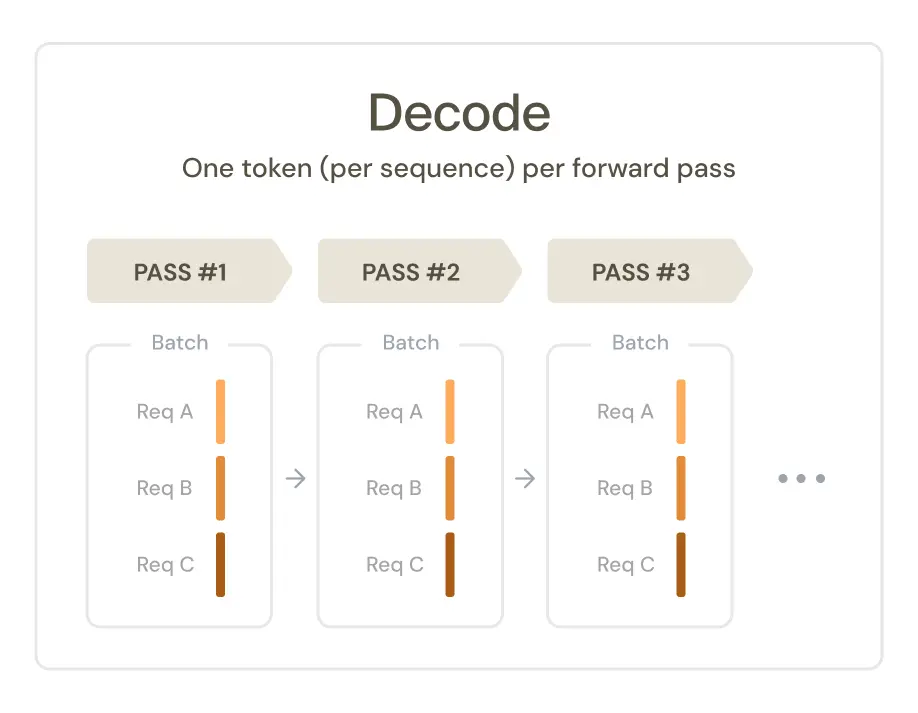
Our approach: design considerations and implementation
Controlling complexity
In any engineering effort, deciding which problems to solve is as important as actually solving them. We carefully considered our use case and made two decisions that helped us avoid unnecessary battles against SGLang internals:
Capturing at tensor-parallelism sync points. Though Kimi K2 Thinking is run across 8 GPUs in our deployment, we avoided the need to use gathering logic to assemble complete activations. Instead, we chose to capture the residual stream after adding the MLP block’s contribution, when the sharded calculations of the current layer have been merged with the aggregate representations of previous layers. This allowed us to get the most useful signal while minimizing implementation overhead.
Opting against CUDA graph support. CUDA graphs are primarily valuable for decode mode, where the overhead of kernel launches is a larger consideration. Since we only needed prefill, we opted not to support them to simplify our implementation.
Shaping SGLang for our workflow
Capable as they are, inference servers do not support our workflows out of the box. We needed to extend SGLang in two ways:
- We needed to ship activation tensors, representing a snapshot of the model’s residual stream at various points in time, off the GPU and save them.
- We needed to capture sufficient metadata for each activation to establish provenance between the tensor and the underlying token in the input dataset.
Shipping activations off the GPU
The quickest way to tank inference throughput is to trigger heavyweight synchronous I/O between the GPU and the CPU.
Given this, how can we transfer large activation tensors off the GPU without blocking the forward pass? And how can we solve for variable throughput when the forward pass, device-to-host I/O, and disk I/O all operate at different speeds?
We accomplished this with an asynchronous three-step process:
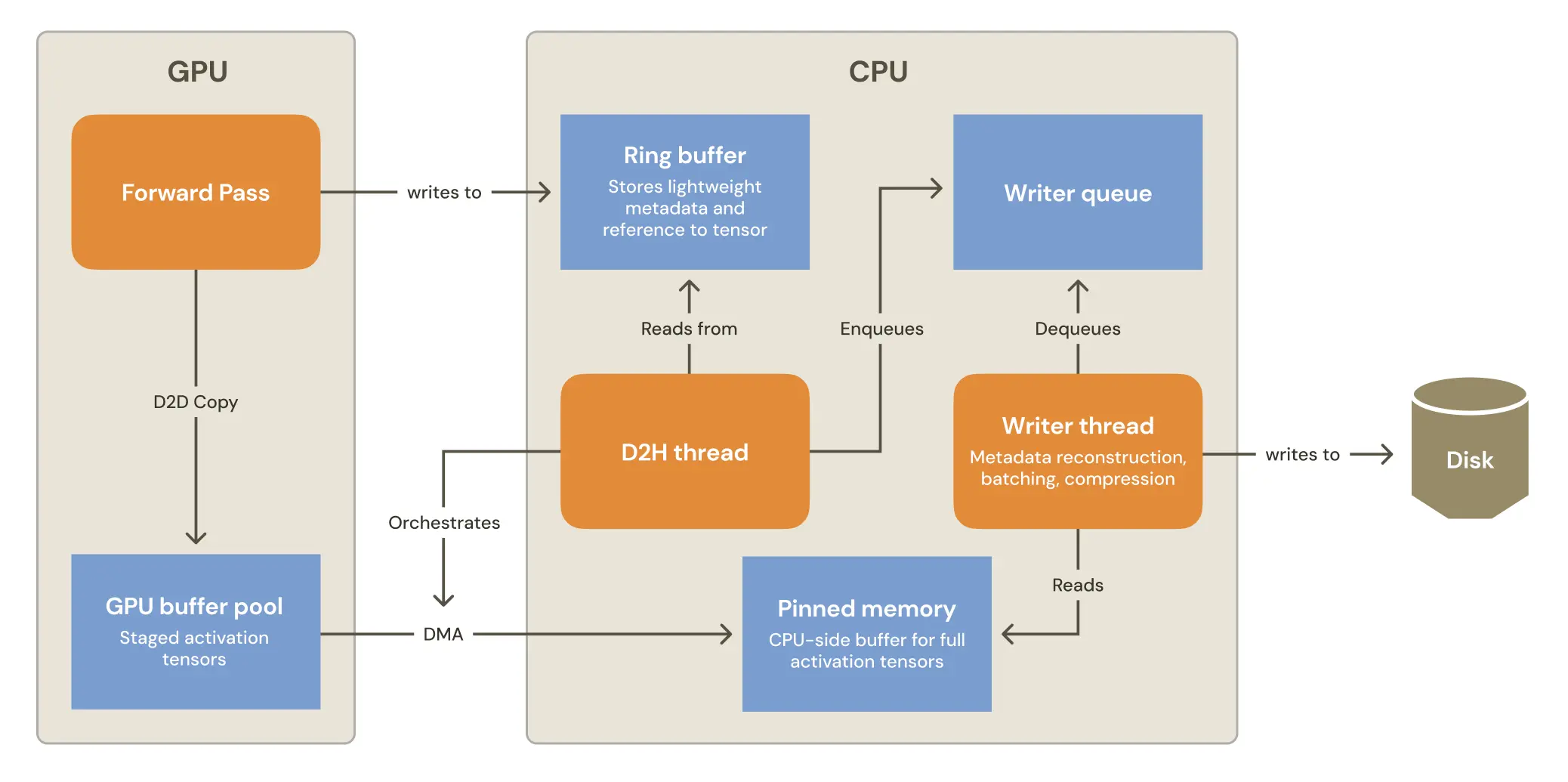
The forward pass is kept as lightweight as possible. We first copy each activation tensor into a GPU-side staging buffer so the capture pipeline can copy it at its own pace, without blocking inference. This device-to-device copy operation is fast, as the activation tensor never leaves GPU memory, and the buffer comes from a preallocated pool of GPU memory, which avoids latency from on-demand allocations.
Even though synchronously transferring full activations to the CPU is a nonstarter, we still need to retain references to those staged tensors in CPU memory. We do this in the lightest way possible by enqueuing a small record (tensor handle, provenance metadata, and a CUDA event handle used for synchronization) into a ring buffer. The data we enqueue is orders of magnitude smaller than the activation payload itself, so the overhead stays manageable.
A sidecar thread handles GPU-to-CPU I/O. This CPU-side thread waits on the CUDA ready_event packaged in each ring buffer record, to ensure that the GPU-side copy operation is complete. At that point, it accesses the tensor using the enqueued metadata, and copies the tensor to a preallocated buffer in pinned CPU memory. Pinned (page-locked) memory enables higher-throughput, asynchronous direct memory access transfers from GPU.
A CPU-side thread reconstructs metadata and writes to disk. A thread running on the CPU is responsible for taking activations from pinned memory and writing them to disk. Because of inevitable mismatches between model inference throughput and disk I/O speed, this thread is responsible for the efficient batching and data compression.
Additionally, the tensors arriving from the sidecar still reflect the complexities of SGLang’s scheduling optimizations: they’re whole batches that may contain many unrelated sequences. Before they’re useful for interpretability, the writer has to separate each batch back into per-sequence activations, tag them with provenance (sequence IDs, token offsets, chunk indices), and emit a canonical record for each sequence.
Metadata: putting the pieces together
Inference optimizations slice, combine, and reorder inputs, so the writer thread needs to handle several SGLang implementation details before persisting activations:
Flattened batches. Continuous batching concatenates tokens from unrelated sequences into a single [sum(seq_lens), d_model] tensor. During the forward pass, logically unrelated tokens within the same physical sequence are masked during attention to ensure tokens only attend to other tokens within the same logical sequence to avoid bogus calculations. In a similar vein, we need to split concatenated sequences into their logical parts to avoid commingling unrelated activations.
Chunked prefill. Long prompts are broken into fixed-size prefill chunks, so a single document’s activations can arrive across multiple captures. The writer composes token offsets within a partial sequence with the per-chunk metadata to recover absolute positions, then tags each sequence slice so downstream jobs can stitch spans back together.
Mode-dependent semantics. SGLang's internal metadata fields have different meanings in prefill versus decode modes. Fields like seq_lens refer to different things depending on context — so our metadata mapping code needs to be aware of the inference mode.
In short, the CPU writer reconstructs per-sequence records with consistent provenance so downstream interpretability pipelines can consume activations without worrying about the internals of SGLang.
Results: What we built
An efficient pipeline
We can harvest 3 billion activations for a trillion-parameter model, in an overnight run. We achieve 14,000 tokens-per-second when activation harvesting on an 8 GPU node.
With ten concurrent nodes, that’s a six-hour job. For context, a more naive approach on the same hardware would take closer to a week.
Steering a trillion-parameter brain
With three billion activation tensors in hand, we trained a sparse autoencoder on Kimi K2 Thinking – and discovered that it has some interesting internal representations:

Given these features, we can steer the model:
The fact that we can steer the chain-of-thought of a coding model is worth emphasizing. Generally, prompting a model affects the model outputs, but not the underlying reasoning trace.
We can even steer in real time, turning features up or down as the chain-of-thought rolls out!
While the implementation of steering is out of scope for this blog post, it’s worth noting that the implementation was built on top of our activation harvesting inference server work. The engineering choices made when reading the internal state of models streamlined the process of modifying the internal state itself.
See our demo at South Park Commons for more!
Engineering is core to interpretability
One pillar of interpretability work is research: coming up with promising ideas that help us advance the fundamental science of understanding AI systems. Another is infrastructure: getting into the nitty gritty details of low-level systems – buffer sizing, I/O optimizations, metadata integrity – that allow us to apply our research in the real world and bring interpretability to the frontier.
We do both at Goodfire. If you’ve found yourself drawn to either side of this work, we’d love to talk to you.
We’re hiring
We're growing quickly and looking for agentic, mission-driven, and kind people who want to build the future of safe, powerful AI. Join us.