
Contents
Today, we're excited to announce a $150 million Series B funding round at a $1.25 billion valuation. The round was led by B Capital, with participation from Juniper Ventures, DFJ Growth, Salesforce Ventures, Menlo Ventures, Lightspeed Venture Partners, South Park Commons, Wing Venture Capital, Eric Schmidt, and others.
We started Goodfire because we saw a problem with how today's AI models are built: every frontier model is a black box, making critical decisions while behaving in unpredictable ways not well understood by science.
We decided to change that by pushing forward the frontier of interpretability—the science of how neural networks work internally—letting us “open the black box” to understand and edit models.
Since then, we've built a world-class team drawn from frontier labs and top research universities, and partnered with industry leaders like Arc Institute, Mayo Clinic, and Microsoft to deploy our technology. We've developed novel techniques to decompose model internals, reduced hallucinations in an LLM by half using interpretability-informed training, and identified a novel class of Alzheimer's biomarkers by reverse-engineering a biological model.
Along the way, we've only grown stronger in our conviction that interpretability is critical to building models that are powerful, yet also reliably steerable and safe. While we've accomplished a lot, there is a lot left to be done.
What we believe
Never in history have we deployed such a transformative technology so quickly with such limited understanding. Foundation models are now writing significant amounts of production code, running loose on the internet, and integrated into the military. Yet their internal decision-making remains opaque, and the black-box approach to shaping their behavior is ham-fisted and prone to bizarre failures.
In order to unlock the promise of safe, powerful AI, we need a deeper and more principled understanding of what we're building.
Luckily, the black-box approach is an unnecessary handicap: there is deep, intricate structure inside of models wherever we look, and we would be remiss not to use it. We can use interpretability tools to instruct and shape models, giving us more deeply aligned systems, and we can also use them as microscopes to understand the vast new knowledge that models learn about our world.
“Interpretability, for us, is the toolset for a new domain of science: a way to form hypotheses, run experiments, and ultimately design intelligence rather than stumbling into it.”
Eric Ho
CEO of Goodfire
What we're building
At Goodfire, we're building towards a future where we can understand what models are doing at a fundamental level, and leverage that understanding to build models in a more principled, aligned, and useful way.
To that end, we've built a “model design environment”: a platform that uses interpretability-based primitives to get insights from models and data, improve model behavior, and monitor them in production. We use this environment internally for research, and deploy it forward with our customers, collaborating in a shared environment. It's built for two primary use cases:
- Intentional design of models, e.g. interpretable training pipelines, inference-time monitors
- Scientific discovery via model-to-human knowledge transfer
Intentional design
Intentional design is the first pillar of what we do: we're building new ways to understand what a model is doing, debug its behavior, quickly and precisely reshape it, and monitor it in production.
One part of that, which we're beginning to invest more energy into, is training. Today's approach to training models seems broken to us: we take a bunch of data and throw it at the model, and then watch metrics and loss curves. For the most part, we don't know why things change or how they change. Clearly there must be a better way—one that lets us train models with richer feedback about what exactly to learn, what to pay attention to, and what parts of their responses they got right and wrong.
That's what we're building our platform to enable.
Interpretability enables us to detect behaviors we want to change, and specifically intervene on the parts of the model corresponding to those behaviors. For example, we recently used interpretability to RL an LLM to reduce hallucinations by half:
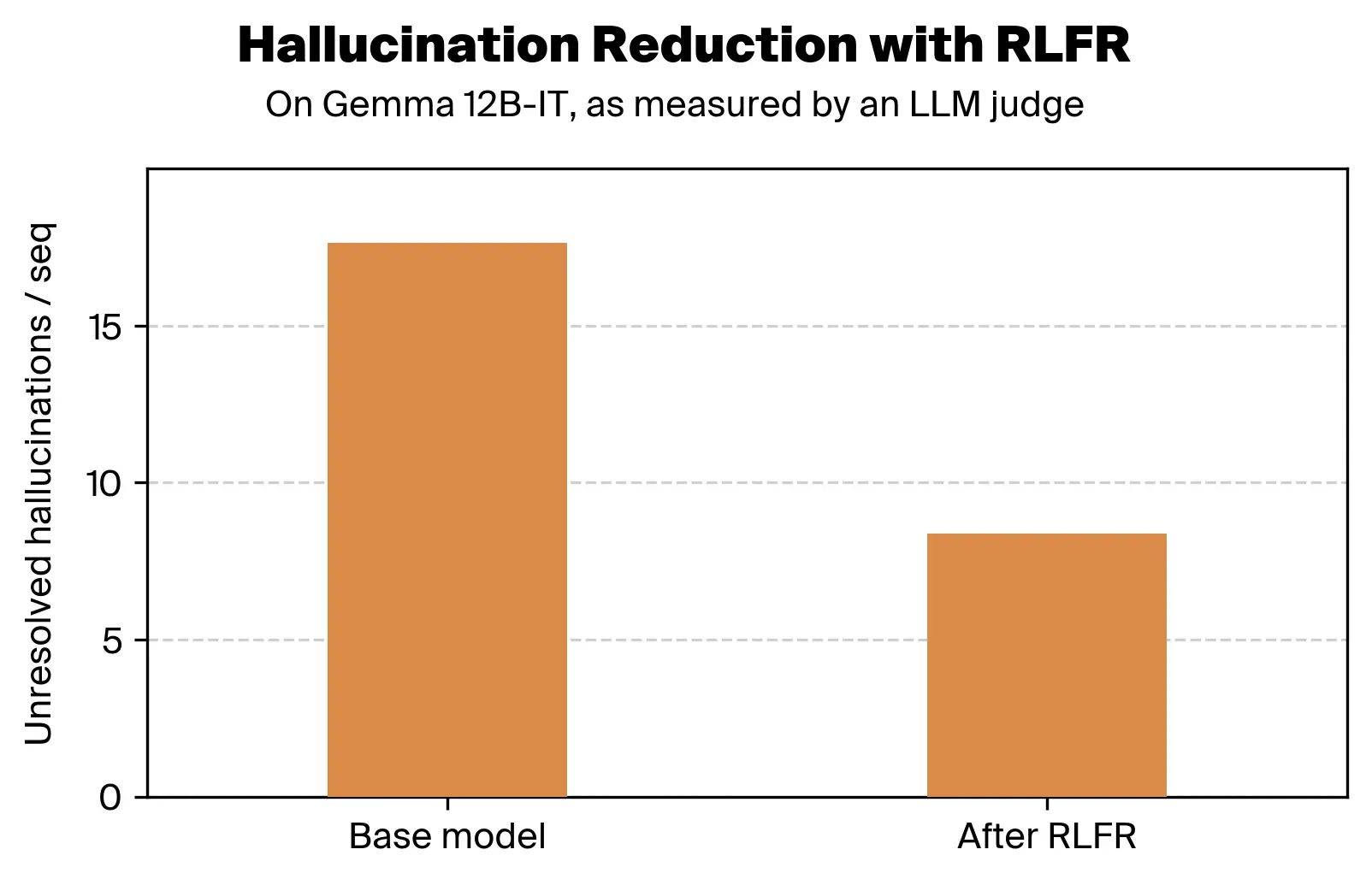
We think intentional design paves the way for a paradigm shift in how we train and deploy models, with much more robust, specific, and efficient control over what models learn and how they behave in production.
We engage deeply and selectively, partnering with teams building high-stakes or frontier systems where understanding and control are essential. If your organization is interested in partnering, we'd love to hear from you.
Scientific discovery
Narrowly superhuman models are here, and they keep getting better: on tasks in domains from molecular biology to materials science, neural networks surpass human experts. The knowledge contained in such models is tantalizing. They seem to have learned things unknown to science—but any such knowledge is locked inside a black box.
Interpretability tools can help us unlock it.
This is the case for the second pillar of our platform: scientific discovery via interpretability-driven model-to-human knowledge transfer. A paper coauthored by our cofounder Tom McGrath gave us the first proof of concept, extracting novel chess concepts from AlphaZero and teaching them to a grandmaster. Now, we've peered into an epigenetic foundation model built by Prima Mente, and identified a novel class of biomarkers for Alzheimer's detection, the first major finding in the natural sciences obtained from reverse-engineering a foundation model.
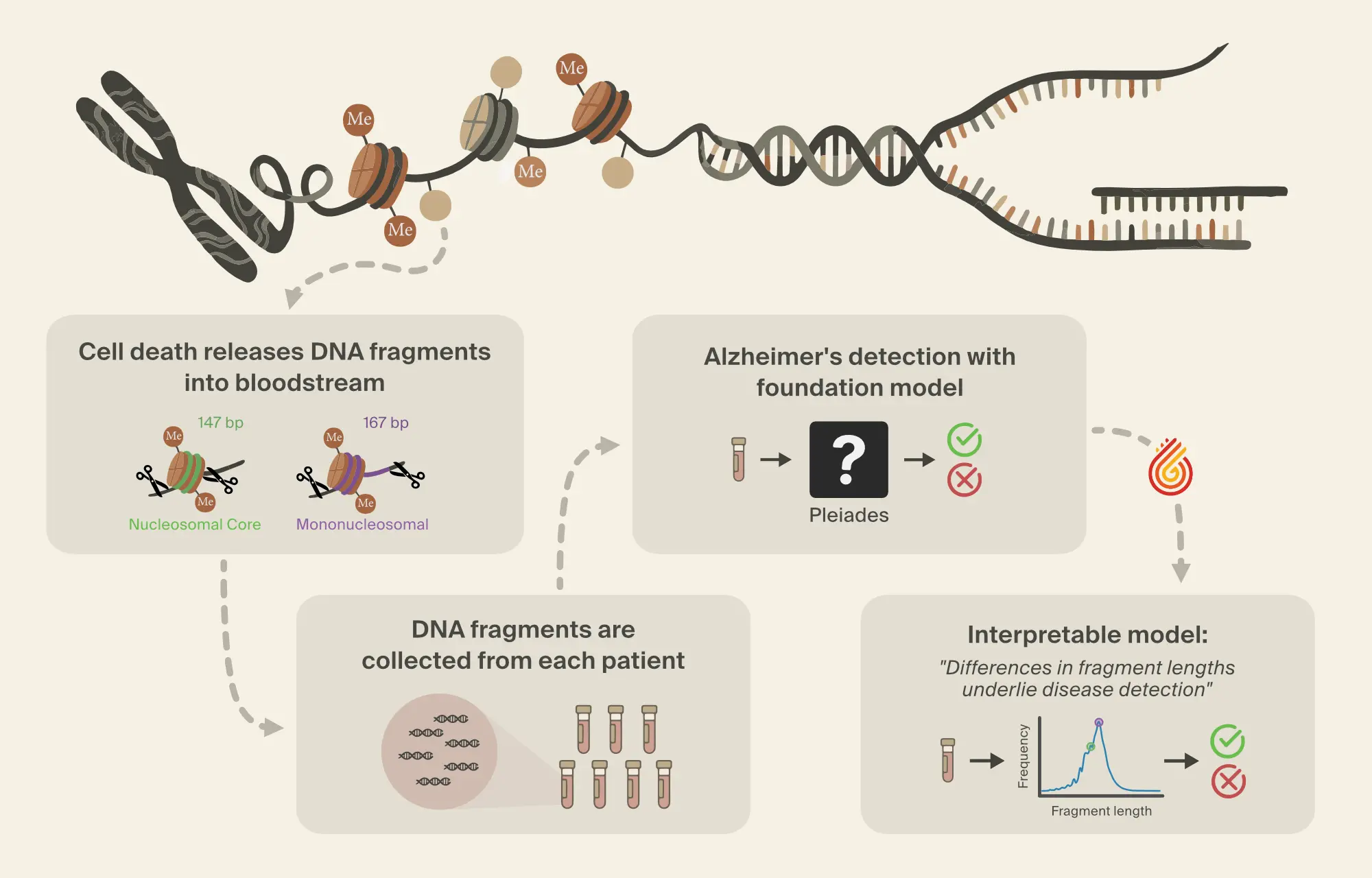
In addition to Prima Mente, we're working with partners like Arc Institute and Mayo Clinic to discover more novel science, improve models, reduce confounders, and ensure AI-driven insights are scientifically sound and clinically relevant.
We believe that interpretability is the core toolkit for digital biology. As large foundation models become central to digital science, interpretability methods are our microscope for understanding what the models have learned from the vast data they've seen.
Foundational research
At our roots, we are a research lab. Beyond our work on our platform, we're continuing to invest in several key directions in foundational interpretability research, which we think have a chance to change the entire field of ML. We fundamentally believe in basic research—the field of interpretability would not exist without it—and we're compelled by a deep curiosity about how neural networks work.
We think we've only scratched the surface of what's possible with interpretability, and foundational breakthroughs are the path towards unlocking more powerful tools.
Towards alignment
We think that alignment, transparency, and reliability are nonnegotiable as increasingly powerful models are deployed.
Our mission is to solve these problems—to be able to debug and fix when models mess up, and to specify exactly how AI behaves, with precision, in a way that generalizes to new contexts. This is an ambitious goal, but we think interpretability will be critical to get there: it promises us transparency into what models are doing and why, the ability to understand how models will behave in contexts that can't otherwise be replicated, and the tools to efficiently intervene on them with precision, depth, and intelligence.
That is the value that we provide: our partners and customers—and, we believe, the world at large—want the ability to reliably design, edit, and debug models before we can trust them to do important work. We think the directions we're working on will give us traction on critical parts of that solution, while giving us empirical feedback from working on real models and applications.
Ultimately, we want a future of human agency and prosperity, where AI can usher in incredible advancements in human health and science. There is much work left to do, but every new research breakthrough brings us one step closer.
Our team

Our Chief Scientist Tom McGrath led a research team at Google DeepMind, but believed that doing his life's work meant going all in on Goodfire. We left startups and nonprofits we founded, moved to San Francisco, and put academic career paths on hold. For months, our office was a windowless room in South Park Commons.
Everyone here took a chance on what some would call impossible ambition. We came together because we share a conviction: that interpretability is the most important technical problem of our generation, and that we might be able to solve it.
Build with us
We're growing quickly and looking for agentic, mission-driven, and kind people who want to build the future of safe, powerful AI. Join us.
If your organization is interested in custom, interpretable, frontier models, we're bringing on a few select design partners. Reach out to us to learn more.