
You and Your Research Agent: Lessons From Using Agents for Interpretability Research
We’ve been using AI agents to assist with interpretability research for the past several months. In this post, we’re sharing some of the lessons we’ve learned: how agents for experimentation are different than agents for software development, where they perform well, and where they still fall short. We’re also open sourcing a basic implementation of the most important tool we’ve found for enabling effective agentic experimentation — a general-purpose Jupyter server/notebook MCP package — and a suite of interpretability tasks that can be run using the tool.
Contents
Developer agents versus experimenter agents Experimenter agents in action When you give an agent a notebook Interactivity Organized & Traceable Outputs Security Validation & Other Challenges for Agentic Research Validation Mitigations Context Engineering Ensembling & Other Blessings of Agentic Experimentation Ensembling & Parallelization Shallow validation debt Cross-domain knowledge Other lessons we’ve learned Our open source notebook tool & interpretability task suite The future of agentic researchBreakthroughs in humanity’s understanding of complex systems like cells, galaxies, and particles are made possible by tools that augment our natural capabilities. Artificial intelligence is no different; modern neural network models are too vast for us to understand without powerful tools. Fortunately, AI itself serves not only as a subject of inquiry, but also as a technological accelerant for AI researchers. We believe the field of interpretability will soon reach the point at which “scaling laws” emerge, allowing us to predictably spend compute to make models more interpretable, reliable, and controllable. AI agents are likely to play a major role in helping us get there.
At Goodfire, every one of our researchers and engineers leverages AI tools daily. Having built internal infrastructure for agentic workflows and — equally importantly — spent significant time practicing the skills and building the habits of working with AI, we’d like to share a few lessons we’ve learned. These lessons are informed by our particular research focus on AI interpretability, but we believe many best practices are broadly applicable.
Developer agents versus experimenter agents
Capable agents should, in principle, be able to use code to both develop effective software and to discover new things via in silico experiments. Both are domains of computational reasoning. But these two tasks have very different requirements, and most of today’s agents are built for the former. The asymmetry in favor of developer agents over experimenter agents exist for a few reasons:
- Data: the training data available for “building good software” (e.g. public repositories, issue trackers, and Q&A forums) far exceeds the data available for “running good research experiments.”
- Demand: more users want agents that can complete software development tasks (writing front-end code, fixing bugs, adding a new feature to an app) than agents that can run research experiments.
- Benchmarks: the benchmarks that define progress for agents overwhelmingly focus on software-oriented tasks: SWE-Bench, instruction-following, and QA metrics that can be automatically scored against predefined datasets.
Developer agents help you build or fix something — their output is a durable software artifact that is ideally efficient, robust, and maintainable. Experimenter agents help you learn or discover something — their output is a completed experiment whose conclusions are ideally valid, succinct, and informative.
We use agents for both types of tasks at Goodfire. Since public examples of experimenter agents are less common, it’s helpful to begin by showcasing some tangible instances of how they can be used in practice. Here are a few representative examples of our experimenter agent, code-named Scribe.
Experimenter agents in action
Exploring Features in a Genomics Model
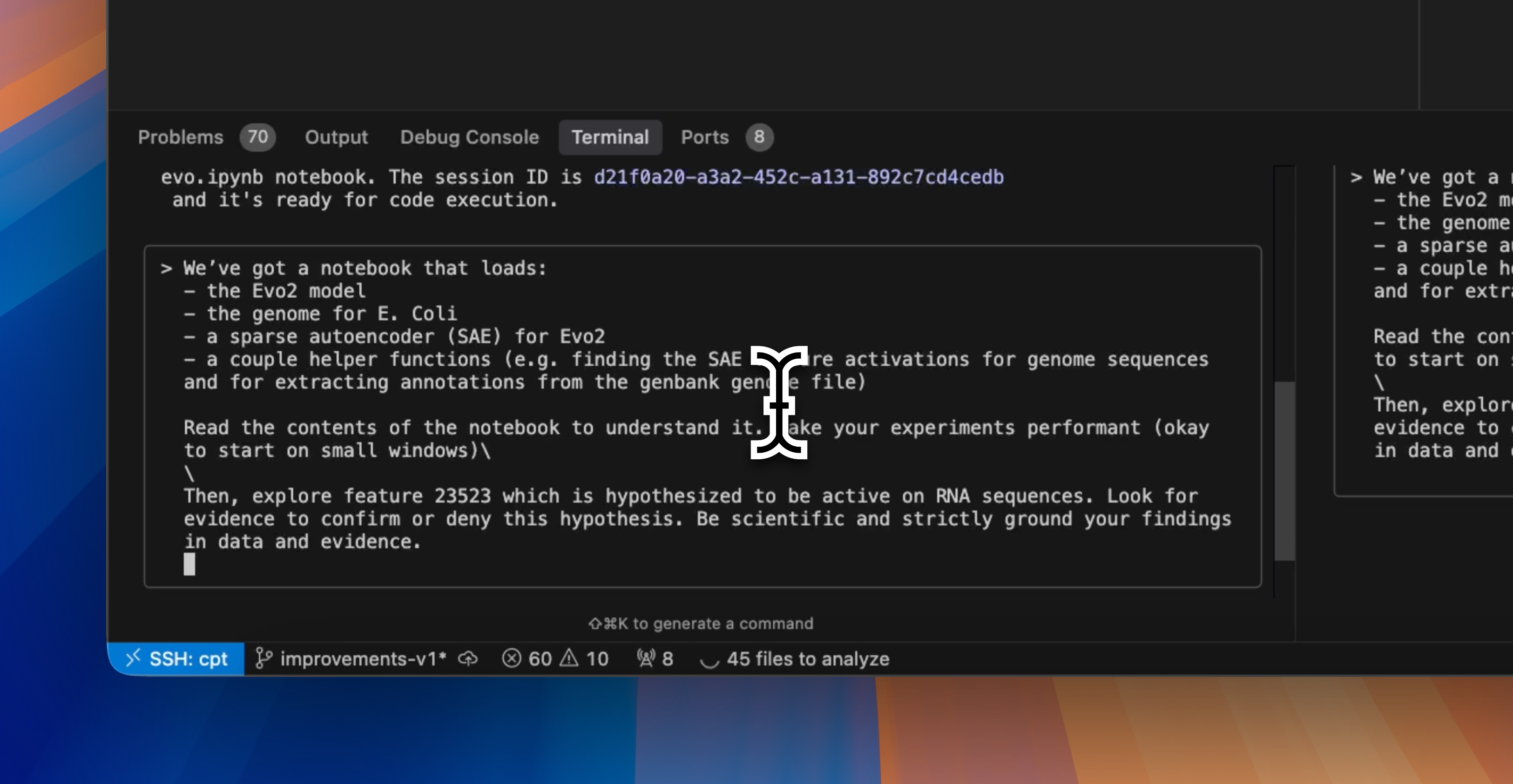
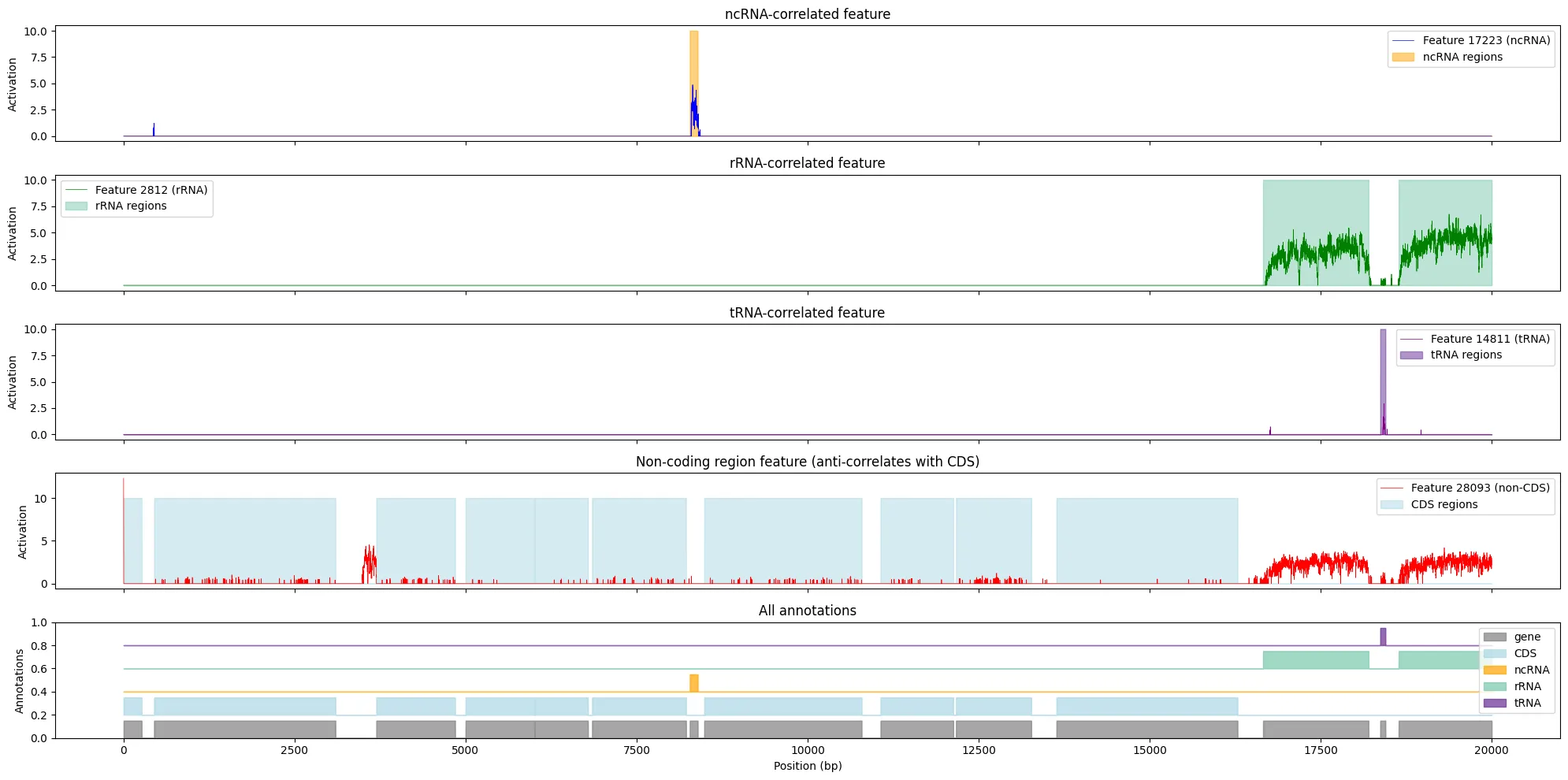
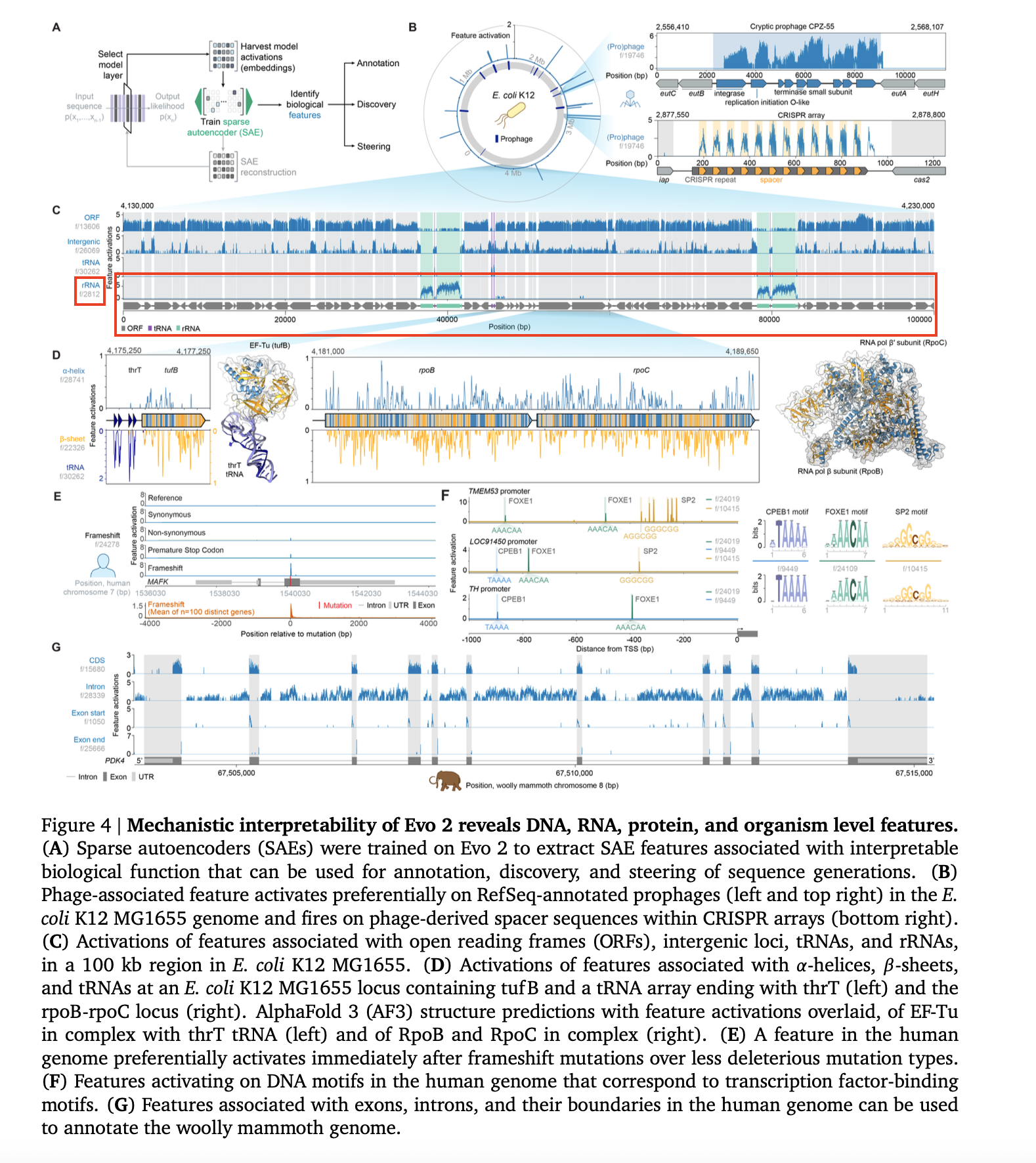
When testing an early version of Scribe (our experimenter agent), we gave it an extremely open-ended question to test how it would break the problem down and how long it would run for. We presented it with example code demonstrating how to load and use Evo 2 (a genomics model), a sparse autoencoder (SAE), and a dataset containing the genome for E. coli. We then asked the agent to “find interesting SAE features” related to known biological concepts. The agent identified several features of interest and presented its results with a detailed output figure. To our surprise, the agent (re)discovered an rRNA-correlated feature that researchers from Goodfire and Arc Institute had found and included in the actual Evo 2 preprint paper.
Finding Eigenvectors for Vision Transformer Weight Pruning
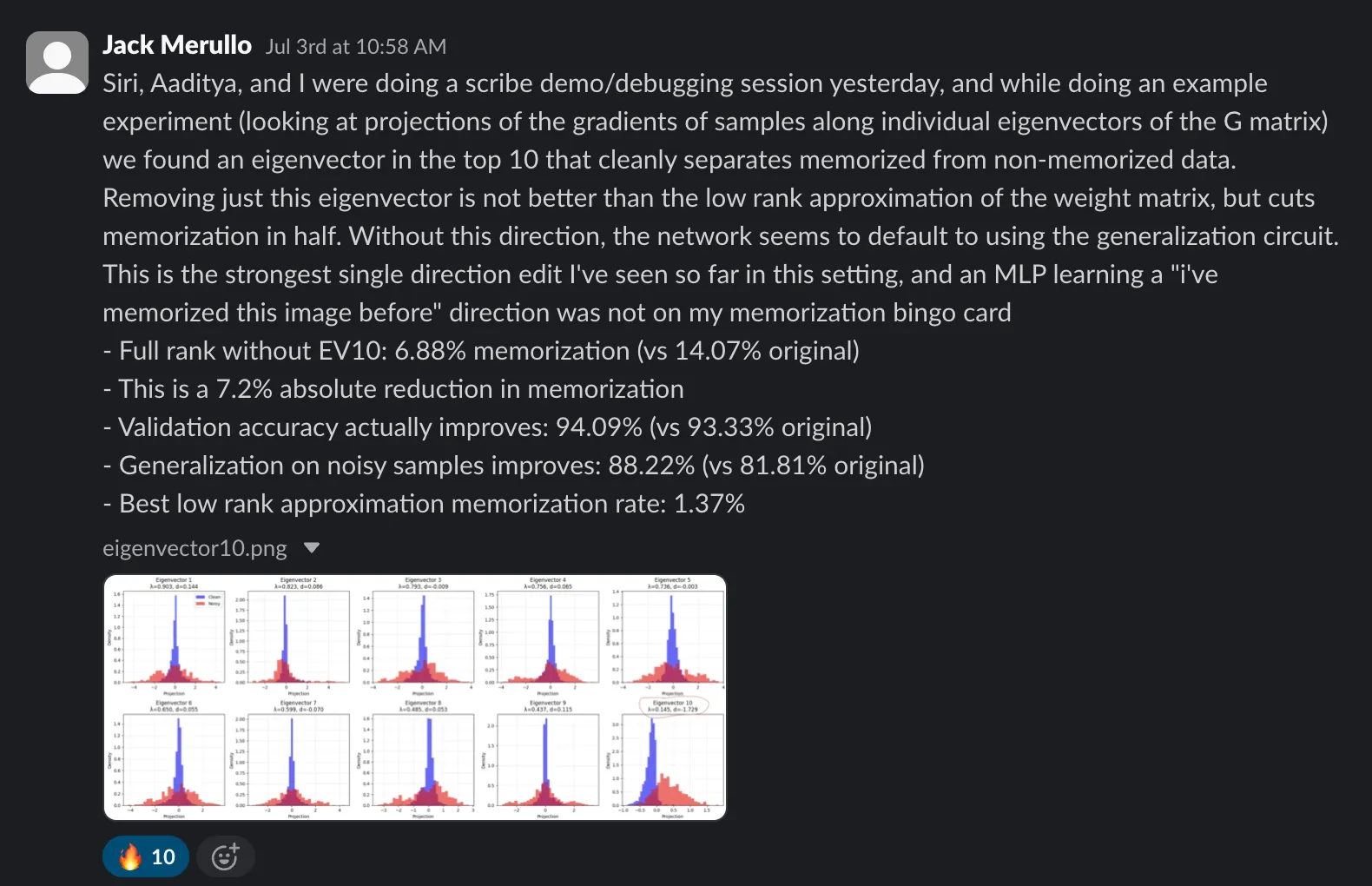
In another instance of Scribe producing a surprisingly useful result during a “test run,” it identified an eigenvector that could be used to prune weights from a vision transformer to reduce unwanted memorization.
Steering a Diffusion Model via Contrastive Examples
Given how many experiments require working with figures, plots, and images, experimenter agents must have tools that let the underlying models leverage their multimodal capabilities. This is especially important for our work with generative image models like the ones that support our Paint With Ember research preview. Agents help us quickly test and validate ideas — such as attempting to steer the Flux diffusion model by finding the difference between activations of smiling and frowning faces and injecting this vector into new images. Given a minimal description of this task (inspired by this paper) the agent successfully executed the strategy and produced a useful poster-like output:
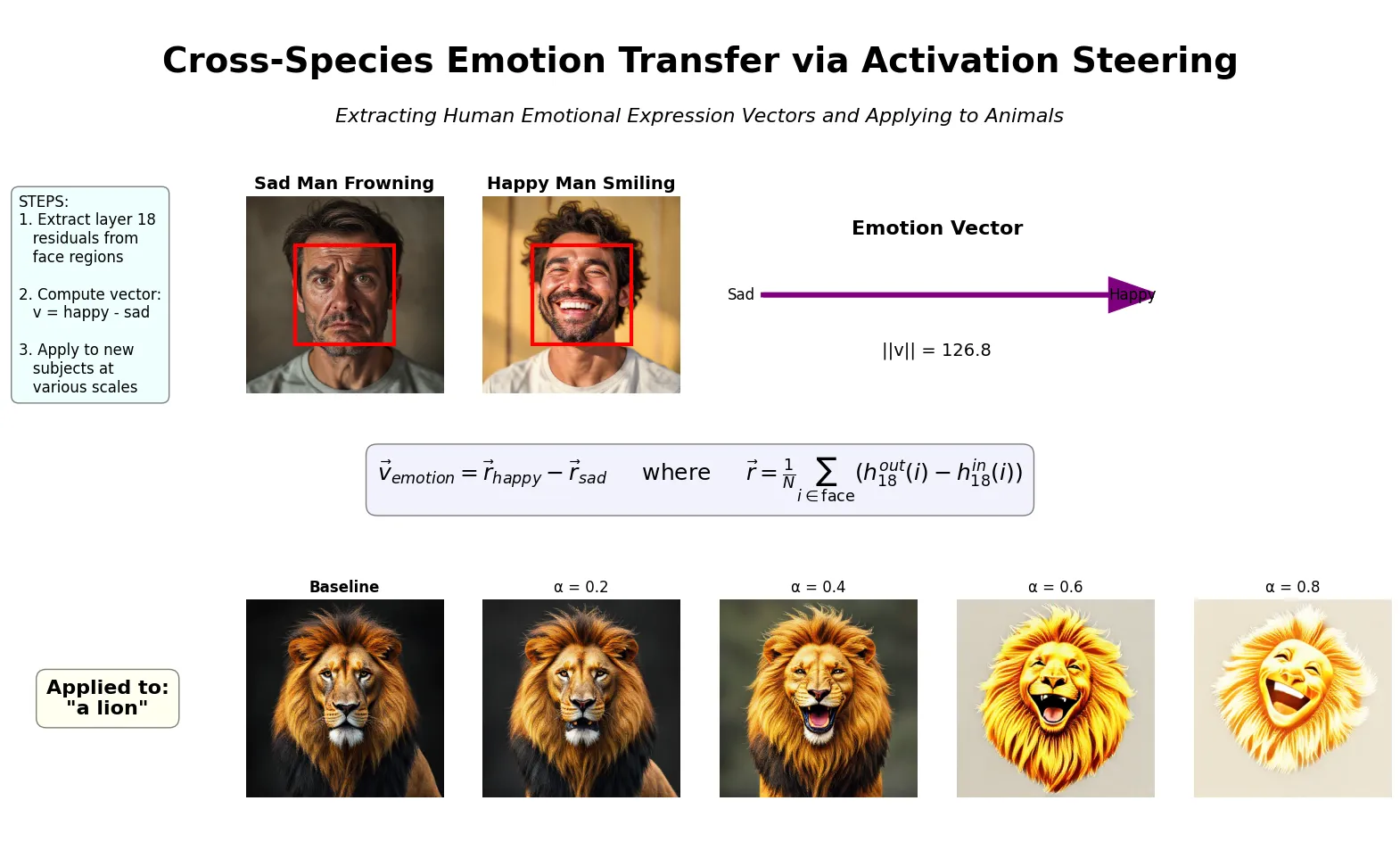
Localization & Redundancy of Memorization
Here, our agent performed an experiment for localizing the neuron sets responsible for memorization (GPT-2’s ability to recite the digits of pi). Scribe performed the experiment and reported the final results and analysis to help understand the redundancy of information storage in LLMs:

As these examples show, experimenter agents take on tasks that often look very different than software development.
Each type of work requires a distinct set of context and tools. It turns out one tool in particular makes a big difference for research tasks: agents are far more effective at completing (or even to assisting with) experiments when you let them use a Jupyter server and notebook.
When you give an agent a notebook
The single biggest lesson we’ve learned when using agents for research is to give them direct, interactive, stateful access to a notebook. Many of the properties that make Jupyter notebooks a go-to tool for researchers also makes them valuable for agents.
Interactivity
Jupyter servers leverage an IPython kernel to enable sessions with REPL-like interactivity. This means you can import packages, define variables, and load large models once at the top of your notebook which are then available for use in all downstream cells for the duration of the session. Most current agents, on the other hand, are only able to run code either by writing and executing scripts or by using python -c "…" in the shell.
Setup code can be lengthy, both in terms of tokens and runtime. This makes it especially frustrating and inefficient when an agent executes a script that runs for several minutes only to encounter a trivial error just after importing packages and loading models. In a notebook, the error can be fixed and tested immediately by re-running a single cell; agents working on scripts must update a file and re-run the entire program from scratch, including the setup code. This greatly reduces iteration speed and experimental throughput.
While various coding agents are adding support for notebooks, we’ve found them to be lacking. We built an MCP-based system that lets agents actually execute code and receive output from Jupyter’s messaging protocol (including output like text, errors, images, as well as control like shutdown requests) as a tool call. This makes for a nicer copilot experience than agents that merely edit notebook files and require users to manually execute the code and report output back to the agent. It’s also nice to be able to alternate between conversational turns (planning, discussing results) and having the agent run pieces of the code a few cells at a time (do something, chat, iterate, do something new) as opposed to running entire programs as atomic units.
Organized & Traceable Outputs
We’ve found that when agents use scripts to execute code, they are often reluctant to edit existing files, preferring instead to create new versions with changes applied. The result is a disorganized mess of near-duplicate files with confusing names like run_analysis.py run_analysis_new.py run_analysis_parallel.py run_analysis_fixed_parallel.py. Without notebooks, agents also tend to produce a mess of image file outputs, leading to extremely cluttered and confusing projects.
Notebooks combine code, results, and markdown in a single file, scoped to the task at hand. This is a more convenient way for agents to present the final outputs of an experiment and to store and share these results for later review. We’ve set up our experimenter agent to name each notebook with a timestamp and a descriptive label, making it easy to reference past experiments as atomic units of research. This organization is not only user-friendly but also necessary for increasing the throughput of agentic experimentation since human verification is the main bottleneck to scaling experiments performed by research agents.
Security
It’s important to note that giving agents the ability to execute code via tool calls to a Python kernel allows them to bypass the security permissions built into many systems like Claude Code, Codex, and Gemini CLI. Without adding custom security checks or using sandboxing, agents can pass arbitrary code to the tool, which they can use to bypass default permissions for file access, bash commands, and read/write privileges. For instance, we have seen agents attempt to run pip install commands via their native bash tools, be blocked by permissions settings, and then realize they can run !pip install commands via tool calls to the notebook server.
Validation & Other Challenges for Agentic Research
Validation
In software engineering, correctness is anchored by unit tests and whether or not code can compile or run without errors. When a developer agent adds a new feature or fixes a bug, it can validate its output by running the test suite and iterating until the checks pass.
In research, there is no such verifiable reward. This makes it difficult for research agents to decide (a.) when an experiment should be considered “”complete,” and (b.) whether or not the results are correct. When should the agent give up and accept a null result, versus pushing forward and trying a few more strategies? How should it calibrate skepticism when results look “too good to be true”? These are skills that are impossible to quantify or to precisely describe in general terms. They’re matters of intuition and “vibes” that researchers build up with experience.
Models currently lack this tacit expertise, and our experience is that agents are biased toward optimism. This behavior takes many forms:
- shortcutting: deliberate reward hacking or cutting corners — e.g. generating synthetic data when unable to resolve a bug that’s blocking the production of final results, often justified with reasoning like “since I’m blocked from downloading the requested dataset, I’ll produce a figure displaying the final log-linear trend that we’d expect to see for this task”
- p-hacking: presenting negative results with a misleading positive spin — e.g. describing an F1 score of 0.5 as “meaningful signal”, or selective reporting of results akin to p-hacking, such as emphasizing the 1/100 inputs that shows a positive result in a final writeup
- “eureka”-ing: lacking skepticism, tending to naively interpret bugs as breakthroughs — e.g. making an error that produces obviously flawed results and accepting them at face value (“miraculous results” of 100% accuracy)
Mitigations
While many of these behaviors will go away as base models become more capable, there are also ways to mitigate them for the current generation of models via engineered systems. For instance:
Using a post-hoc “critic agent” to review the output of the agent that performed an experiment and call out any errors, methodological flaws, or other limitations:
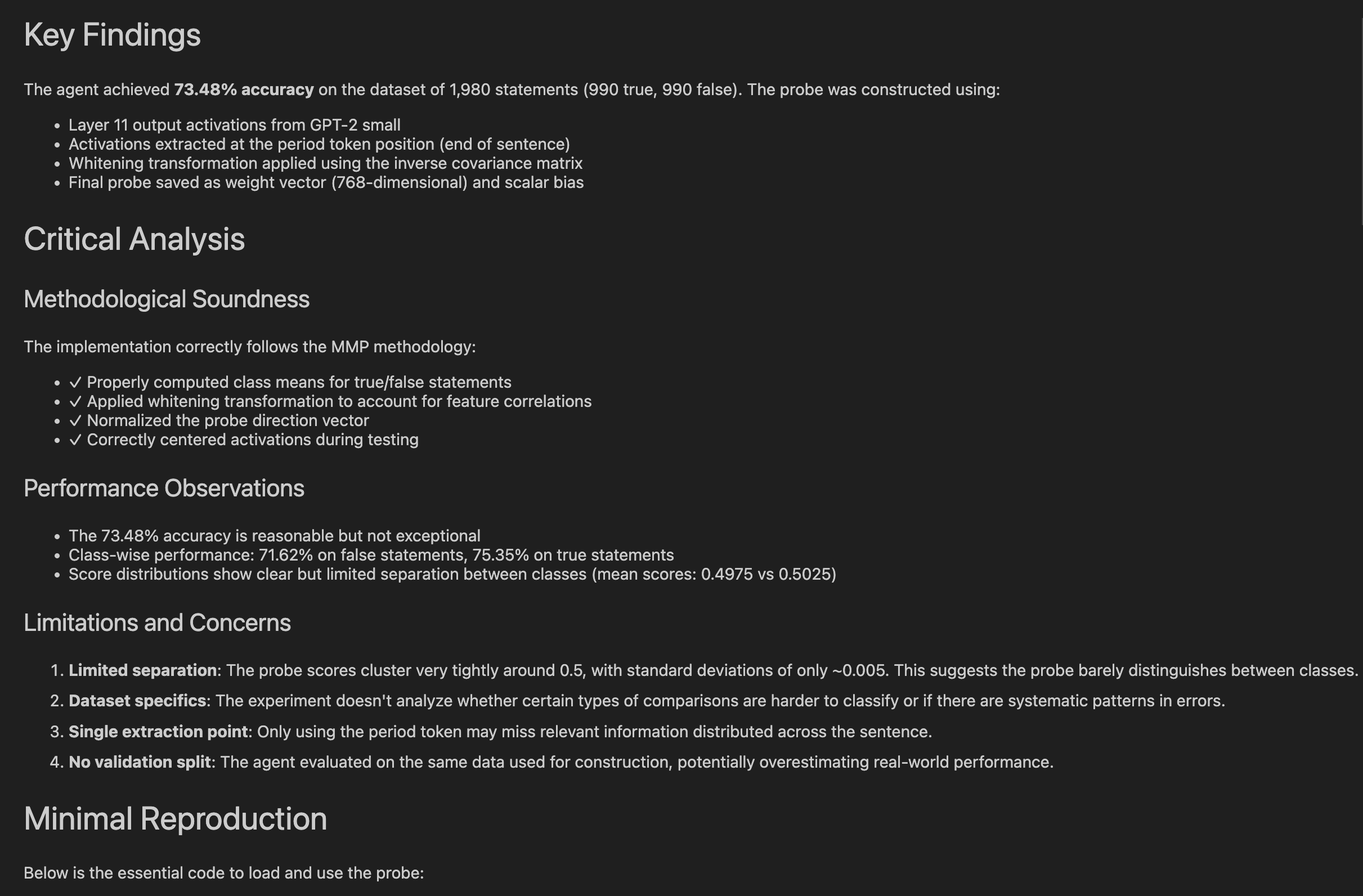
Using a live “critic-in-the-loop” to spot attempted shortcutting and intervene using Claude Code hooks:
Introducing a critic copilot you can chat with on the side about an ongoing session with another LLM, leveraging different base models’ strengths. Here’s a real-life example of GPT-5 spotting an error in Claude Sonnet 4’s experiment code by reviewing Claude Code transcripts:
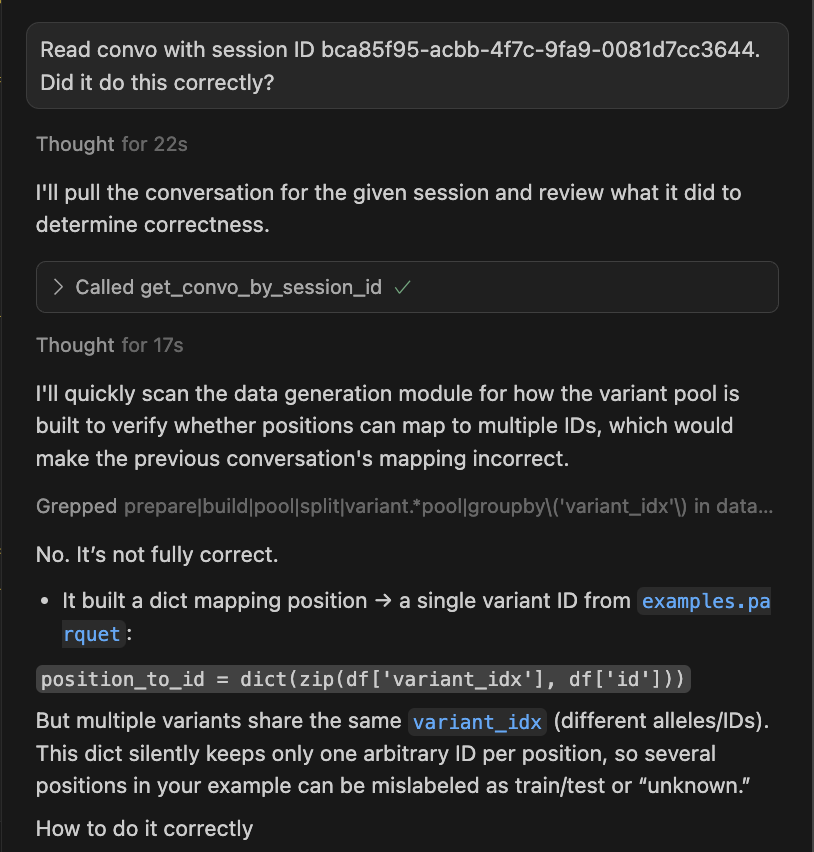
Context Engineering
Context engineering for experimenter agents presents new challenges not faced by developer agents. Software development tends to be more Markovian than research since, as a developer, the current state of a codebase is often all you need to know when adding a new feature or fixing a bug.
Research projects, on the other hand, often lack a single, well-defined codebase to ground new experiments. Much of the context you’d hope an agent would have when trying out an experiment is illegible: discussions of previous experimental results in a Slack thread, ideas you tried a while ago and know are not worth pursuing further, intuitions built up from conversations with collaborators on this project you’ve worked with for weeks.
It’s also difficult to articulate a plan that guides agents through sub-tasks, since research is inherently non-linear. The most ambitious and exciting research questions cannot be reduced to a checklist of steps or even bounded by a predefined stopping condition. You want an agent to explore, following surprising leads and abandoning unproductive ones, but telling it exactly how to balance exploration against focus is difficult.
As a result, we believe many promising “rabbit holes” remain unexplored not because agents are fundamentally incapable, but simply because they lack the right structured guidance or intuition to consider them.
Ensembling & Other Blessings of Agentic Experimentation
Despite these challenges, there are many ways in which running experiments is a task uniquely suited for agents.
Ensembling & Parallelization
For software development tasks, having multiple agents all implement the same feature or fix will at best lead to wasted effort and at worst introduce new bugs as they step on each other’s toes. On the other hand, letting several agents loose on the same open-ended research question often makes sense. The agents will typically take different experimental approaches, and as long as one stumbles upon a useful insight, the aggregate effort was worthwhile. If all agents reach the same conclusion, this is still valuable signal (replication). Meanwhile, parallelization of agent experiments can allow for several distinct ideas to be explored simultaneously, leveraging the fact that research questions don’t depend on one another as tightly as engineering tasks.
Our initial experimenter agent was implemented as an interactive copilot, but to enable greater ensembling and parallelization, we implemented a more autonomous version based on the Claude Code SDK that can run experiments without supervision.
One of the most common instances in which a researcher may choose to initiate several parallel experiments is immediately after a successful initial experiment, as a set of follow-ups. We’ve found that models can produce surprisingly high-quality proposals for follow-up experiments when reflecting on initial results, which can typically be run as a parallel suite.
Shallow validation debt
The proliferation of agents means that human validation time is increasingly becoming the bottleneck to progress on a project. As agentic outputs pile up for human review, there are different varieties of “validation debt” that emerge.
Software development agents can easily create entire applications that are too complex for human overseers to understand, debug, and reason about. This “deep” validation debt makes it difficult for humans to implement their own features or fixes to the code, locking them into continued usage of agents in a vicious cycle that crystallizes the code as a black box.
On the other hand, experimenter agents create shallow validation debt; unreviewed experimental results do not hamper the ability of human researchers to proceed with their work on related questions.
Cross-domain knowledge
At Goodfire, we work across fields like genomics and materials science. Since many of the most interesting discoveries of how models work requires some amount of domain expertise to spot exciting connections, agents are at a great advantage by having an advanced understanding of virtually all areas of human knowledge.
For example, a pure specialist in AI/ML might notice anything particularly interesting about the fact that Evo 2 (a genomics model) seems to behave differently when it sees the nucleotide sequences TAA, TAG, and TGA. But to an agent, it is glaringly obvious that these are not random triplets but rather the three stop codon triplets in DNA.
Other lessons we’ve learned
- Long-term memory is a crucial limitation for current agents. For agents to become true “drop-in employees” that we can treat as genuine research collaborators, there must be some way for them to naturally and effectively build persistent context over the course of a project. Even the best
AGENTS.mdfile can’t possible support the type of continual learning that’s needed. - Don’t get too hung up on building “for agents.” While there is certainly plenty of infrastructure that needs to be built specifically for agents, as agents get more capable and can increasingly be treated as ~coworkers, the resources they need will converge with the resources that teams should already be investing in. Agents perform best when working with well-written, understandable software that has good documentation and resources for new researchers/engineers to onboard — in other words, exactly what teams should have been striving to build even before LLMs existed.
- Using agents is both a skill and a habit. Like any new tool, there’s a learning curve to figure out how to work effectively with agents and LLMs more generally. In any team, some members will be more eager than others to lean into tools like Claude Code, Codex, Cursor, etc. While these tools fit some workflows better than others, it is well worth the investment for everyone, across all roles, to try learning them for at least a few weeks before deciding how to leverage them since the opportunity cost of missed acceleration is high and compounding. At the same time, it’s not worth “forcing it” and adopting tools purely out of FOMO if you genuinely don’t see results after a trying to leverage them.
- Learn from others to realize what you could be doing but aren’t. Setting up shared Slack channels to share best practices is helpful, especially given the pace of upgrades to various tools, and models constantly leapfrogging each other’s capabilities. Often, though, pair agentic programming is an even better way to pick up tricks, both small and large, for getting the most from agents.
- Adopting agents changes the types of tasks you spend time on. It takes a mindset shift to realize that a larger fraction of your time must be spent planning, explicitly writing up your thinking and decisions, supervising agents, reviewing their outputs, and assembling the right context. Although this is currently true for developer agents to a greater degree than experimenter agents, that may not be the case for long. As experimenter agents proliferate, researchers of all levels will take on more PI-like responsibilities.
Our open source notebook tool & interpretability task suite
We are open sourcing a reference implementation of the Jupyter server/notebook MCP system that can be used with experimenter agents like Scribe, along with a CLI adapter to easily run Claude Code, Codex, and Gemini CLI with notebook usage enabled.
To demonstrate this tool in action, we’ve also assembled a suite of interpretability tasks from several papers — including problems like circuit discovery, universal neuron detection, and linear probe analysis — that can be run using Scribe. While these aren’t formal benchmarks (we haven’t performed rigorous auditing, and agent performance can vary due to factors such as difficulty adhering to output formatting), we’ve found them to provide useful directional signals for how agents handle interpretability problems and how they perform using notebooks as tools.
The future of agentic research
Goodfire’s mission is to advance humanity’s understanding of AI so that we can build safe and powerful AI systems. We believe agents have a big role to play in the both the research and the engineering needed to achieve this aim.
As we take on more and more ambitious problems — from uncovering concepts inside reasoning models with hundreds of billions of parameters, to advancing materials science by building models capable inverse materials design, to analyzing genomics models to try to inform the development of diagnostic tools and personalized treatments — we are encouraged by the fact that even as the systems we seek to understand become more complex, our tools are also becoming more powerful.
If this vision resonates with you and you’d like to work on understanding AI systems, advancing scientific discovery, and building with agents, we invite you to join us.
Acknowledgments
Thanks to Dhruvil Gala and Ram Peddu for their work developing and updating the interpretability task suite, Myra Deng for editing and feedback, and Nam Nguyen, Oli Clive-Griffin, and Connor Watts for their work on infrastructure for Scribe.
Citation
Bissell, Mark, et al., "You and Your Research Agent: Lessons From Using Agents for Interpretability Research", Goodfire Research, 2025.
@article{bissell2025research-agent,
author = {Bissell, Mark and Byun, Michael and Balsam, Daniel},
title = {You and Your Research Agent: Lessons From Using Agents for Interpretability Research},
journal = {Goodfire Research},
year = {2025}
}