Train language models with the precision of writing software.
Post-training today is intuition-driven with poor visibility into what your model actually learned. We make the internals visible so you can understand your model's behavior, anticipate failures before they reach your users, and design with intention.
.webp)
What becomes possible
See what your model already knows, and teach it what it's missing.

Predict failures before deployment
Predict how your model will fail before deployment, not after. Surface the failure modes that benchmarks and standard eval pipelines miss.

Turn understanding into better performance
Correct failure modes directly, without retraining from scratch. When you can see what's broken, model understanding becomes model improvement.

Precisely control what your model is learning
Build models from the ground up that are correct-by-design. Shape datasets, features, and rewards to create models your domain requires, with less data and finer control.
Our research in LLMs
See what your model already knows, and teach it what it's missing.

58% reduction in hallucinations by using features as rewards
We trained Google's Gemma 3 12B using lightweight probes on the model's internal representations as reward signals, cutting hallucinations by as much as the jump from GPT-4o to GPT-5 with no degradation on performance benchmarks.
58% hallucination reduction with no degradation on performance benchmarks
~90x lower cost than LLM-as-a-judge
Internal representations used directly as training reward signals
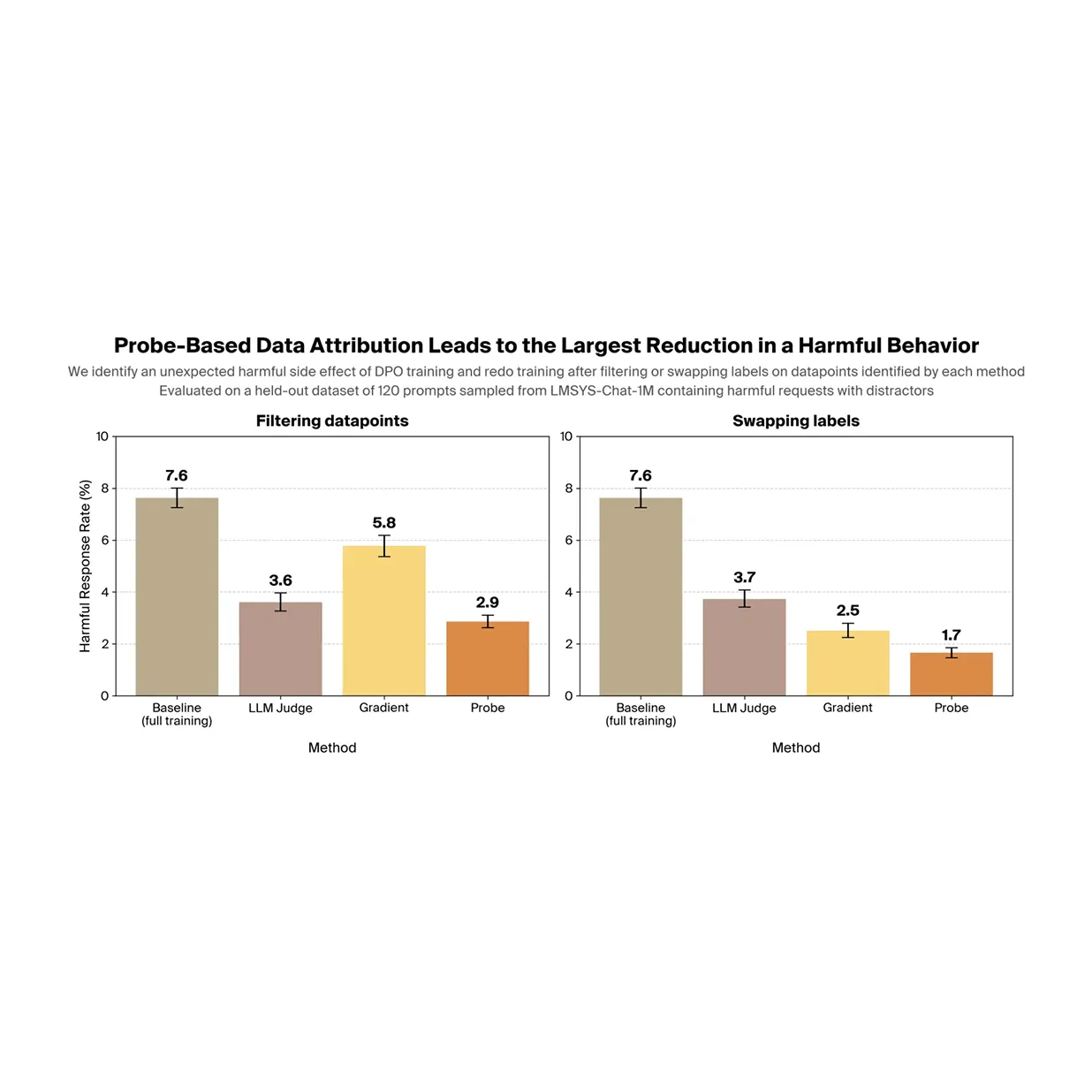
Using data filtering to mitigate undesired side-effects of post-training
Post-training can introduce undesired side effects that are difficult to detect and even harder to trace to specific training datapoints. We show that a probe-based method can surface concerning behaviors that emerge during LLM post-training, and that probes can identify the datapoints responsible for a specific harmful behavior. Filtering out those datapoints and retraining significantly reduces the behavior.
Probes trace harmful behaviors back to specific training datapoints
Filtering reduces the harmful behavior by 63% without hurting performance
Identified problematic data sources to omit, leading to 84% reduction in behavior

Request Access
Training or fine-tuning an AI model? We partner with companies training foundation models across architectures and modalities to interpret their models. Contact us to learn more.