

Context
Founded in Tokyo in 1997, Rakuten is a global technology leader in services that empower individuals, communities, businesses and society, serving over 44 million monthly active users in Japan and a total of two billion customers worldwide.
In 2024, Rakuten and Goodfire partnered to explore ways to make Rakuten AI even more reliable and trustworthy, leading the industry to use frontier interpretability to improve security and prevent customers’ PII (personally identifiable information) from being sent downstream to model providers.
A team of technical staff at Goodfire and Rakuten worked together using Goodfire’s interpretability platform, Ember, to develop and test different methods for PII detection, resulting in a performant, lightweight, and robust guardrail that was deployed to Rakuten’s agent platform.
Outcomes
Rakuten deployed PII guardrails with the confidence that they could mitigate PII leakage at scale with minimal latency and high performance, ensuring the security of customer information across 44 million active users. Our systems exhibited:
- Best-in-class recall,
minimizing PII leakage - Much better cost efficiency and latency
than black-box methods - Strong robustness in production,
performing well in out-of-distribution settings
Our Approach
Our research goal was to develop a system to detect and filter out personally identifiable information (names, addresses, phone numbers, and emails) before they enter downstream processing across Rakuten’s ecosystem, using state-of-the-art interpretability research. The system needed to be:
- High-recall, so no sensitive data slips through
- Lightweight enough to run efficiently at scale
- Trained only on synthetic data, since customer data can’t be used
At a high level, our approach was to use our interpretability platform Ember to test the performance of a portfolio of different methods for Rakuten’s use case. Intuitively, we used the “cognition” of the model itself as the source of information about whether each token is PII, rather than the raw inputs or outputs.
The Results
The research partnership tested which methods best met Rakuten’s needs and data constraints, finding that SAE (sparse autoencoder) probes won out when moving from synthetic training data to real production data—a critical requirement for many real-world monitoring approaches—as well as for non-English and noisy data.
This proof point could offer a potential direction for organizations seeking to address specific kinds of deployment problems. With a custom-built system applied to their AI agents, Rakuten is now able to correctly classify and filter PII prior to downstream processing.
Notably, the SAE probes showed 15–500x cost savings over LLM-as-a-judge setups with comparable performance:
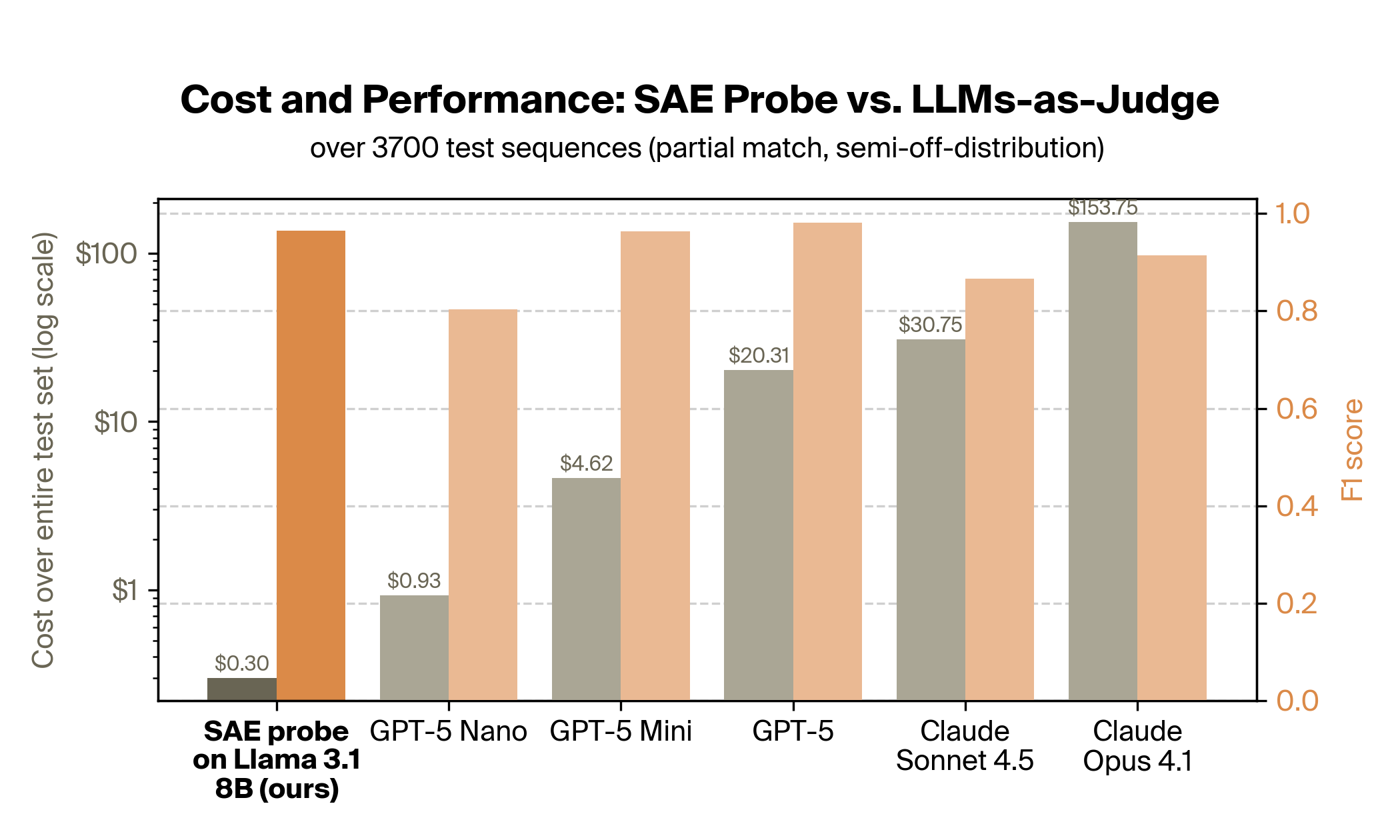
The partnership also found that when using the same model, probing yields dramatically better PII detection than the LLM-as-a-judge approach:
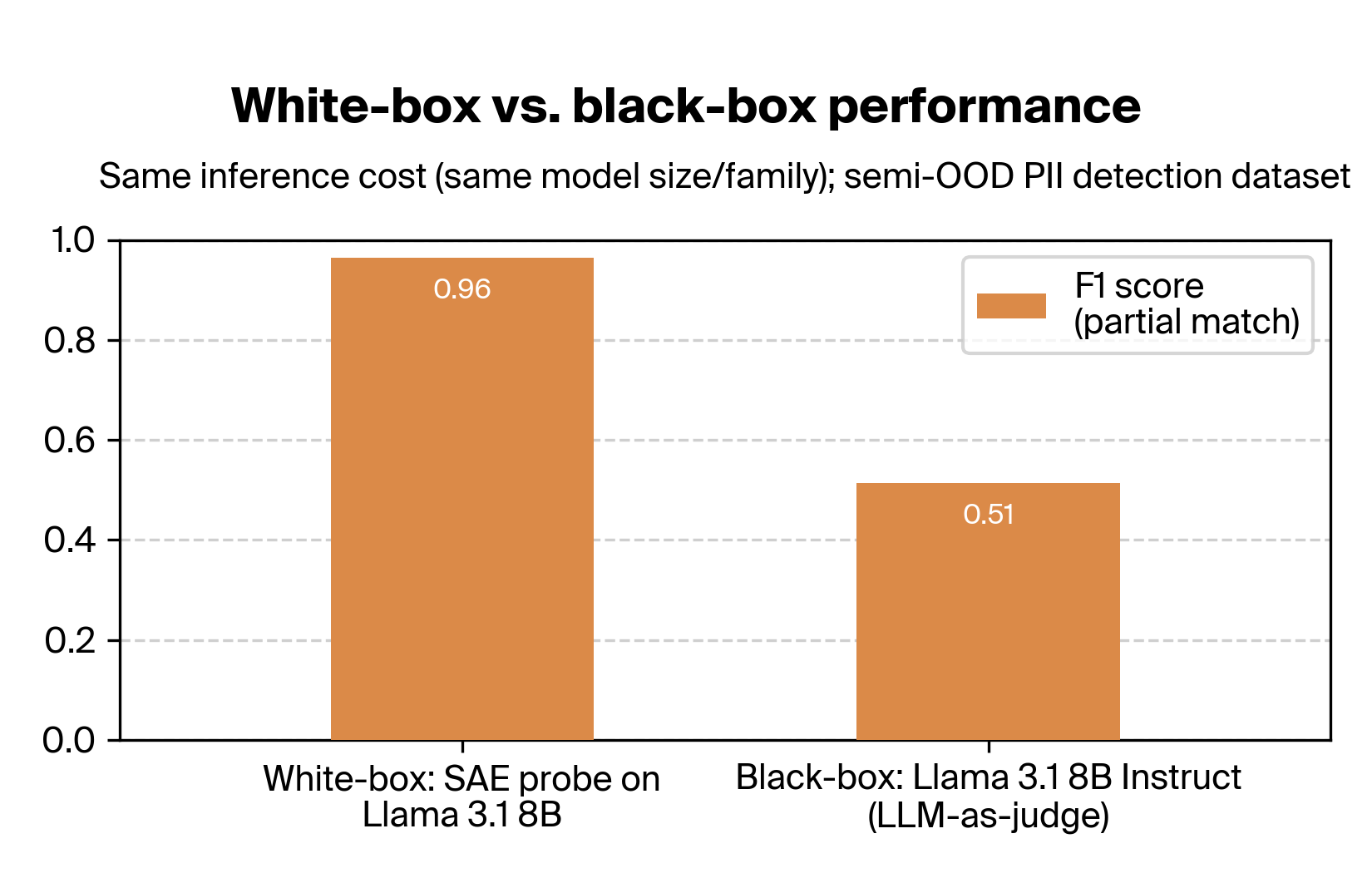
For more details on the approach and results, see our research post Deploying Interpretability to Production with Rakuten: SAE Probes for PII Detection.
