
Introduction
Recent work by Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. and Lindsey et al. [7]On the Biology of a Large Language Model[link]
Lindsey, Jack, Gurnee, Wes, Ameisen, Emmanuel, Chen, Brian, Pearce, Adam, Turner, Nicholas L., Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Thompson, T. Ben, Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. introduced Cross-Layer Transcoders (CLTs) as a method for characterizing information processing across layers and token positions in Transformer language models. We train CLTs on GPT-2 Small and evaluate their ability to recover known computational mechanisms in a well-understood task.
CLTs are designed to provide sparse, interpretable descriptions of neural network computation through learned features and their interactions. We use the greater-than task as our case study because it has a well-characterized circuit that relies heavily on MLP computation - exactly what CLTs are designed to analyze[1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023..
We conduct our analysis in three stages: training CLTs on GPT-2 Small, generating attribution graphs for greater-than task prompts, and performing the same logit attribution analysis as Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.. We find that CLTs successfully identify relevant and interpretable features for the task (including some surprising discoveries like abstract parity features), but we also observe some intriguing differences from the machinery discovered by Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.. We think these results replicate and validate CLTs' ability to semi-autonomously discover interesting structure in language models, but also hint at possible differences in how sparse interpreter models represent and decompose computational mechanisms.
Background
Cross-Layer Transcoders are an indirect approach to circuit analysis that learns sparse features to approximate MLP computation across layers. A core strength of CLTs is their ability to describe both the features a model uses to represent data and the circuits showing how those features interact for given prompts. These circuits are visualized through attribution graphs, which approximate the computation done by the underlying model.
The CLT architecture consists of transcoders that take MLP inputs at each layer and predict MLP outputs for that layer and all subsequent layers. Given a CLT, replacement models can be constructed that combine the CLT with the base model to enable selective analysis of computational components. A full replacement model substitutes all MLP outputs with CLT reconstructions across layers, while a local replacement model passes information to the CLT but preserves the original MLP outputs by adjusting the reconstructions with the reconstruction error. See Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. for details.
We trained CLTs for GPT-2 Small on 100M tokens from the FineWeb dataset [2]The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale[link]
Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf, 2024.. We used an expansion factor of 64, resulting in 49,152 features per layer and 589,824 total features across all 12 layers. For simplicity, we used ReLU as the activation function in our CLTs rather than JumpReLU[3,4]Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Bricken, Trenton, Templeton, Adly, Batson, Joshua, Chen, Brian, Jermyn, Adam, Conerly, Tom, Turner, Nick, Anil, Cem, Denison, Carson, Askell, Amanda, Lasenby, Robert, Wu, Yifan, Kravec, Shauna, Schiefer, Nicholas, Maxwell, Tim, Joseph, Nicholas, Hatfield-Dodds, Zac, Tamkin, Alex, Nguyen, Karina, McLean, Brayden, Burke, Josiah E, Hume, Tristan, Carter, Shan, Henighan, Tom, and Olah, Christopher, 2023. Transformer Circuits Thread.. In training our CLTs and generating attribution graphs, we largely followed the methodology in Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. - we plan to discuss training details and lessons learned in a subsequent post. Our best CLT model achieves an L0 of 79 and 59% token accuracy, consistent with results reported in Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread., and we use this CLT for all of our experiments with the greater-than task.
The Greater-Than Task
The greater-than task provides an example of numerical reasoning where the underlying computational mechanism has been partially reverse-engineered[1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.. In this task, models receive prompts in the format "The {noun} lasted from the year 17{year} to 17", and predict a two-digit year to complete the sentence. Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. demonstrated that when given an input year $\texttt{YY}$, specific MLP neurons in GPT-2 Small work together to suppress predictions for years less than $\texttt{YY}$ while boosting predictions for years greater than $\texttt{YY}$.
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.
Each heatmap shows how strongly each neuron promotes (blue) or suppresses (red) predicted years (x-axis) given different input years (y-axis). The neurons demonstrate clear greater-than behavior, systematically suppressing years less than the input and promoting years greater than the input.
Methods and experimental setup
For the case study below, we construct and analyze a graph for a single prompt: 'The war lasted from the year 1711 to 17'. In doing so, we follow the existing CLT analyses of arithmetic tasks in Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. and Lindsey et al. [7]On the Biology of a Large Language Model[link]
Lindsey, Jack, Gurnee, Wes, Ameisen, Emmanuel, Chen, Brian, Pearce, Adam, Turner, Nicholas L., Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Thompson, T. Ben, Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread., but diverge from Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. which selects features by aggregating statistics for multiple prompts. Again following Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. and Lindsey et al. [7]On the Biology of a Large Language Model[link]
Lindsey, Jack, Gurnee, Wes, Ameisen, Emmanuel, Chen, Brian, Pearce, Adam, Turner, Nicholas L., Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Thompson, T. Ben, Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread., we use this prompt to compute an attribution graph, identify the graph's most influential features, and explore their interpretations using multiple analysis and visualization techniques.
Attribution Graph
Figure 2 shows the attribution graph for the input prompt. We made this graph visualization, as well as the max-activating example visualizations in later sections using Anthropics open-source circuit visualisation tools[5]Attribution Graphs Frontend[link]
Anthropic, 2025. GitHub.. The graph itself is generated by our own reimplementation of the graph construction and pruning algorithms from Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread..
The attribution graph reveals a dense concentration of features originating from input token 11 (the final digit of "1711") and flowing toward the final token position where the model makes its prediction. This pattern demonstrates how the CLT captures the computational pathway from the critical input year token through multiple layers to the output logits, with the highest concentration of feature activations occurring in the later layers near the prediction point. For readers of Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread., note that we did not do the manual step of clustering highly similar features into supernodes.
📱 Interactive Graph Not Available on Mobile
Sorry, this interactive attribution graph does not support mobile devices. Please view this page on a desktop or laptop computer for the full experience.
Three types of nodes are shown: circles represent features, diamonds represent error nodes, and squares represent input embedding features and output logits. Lines between nodes represent edges showing attribution connections. See Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. for detailed explanation of these node types.
Feature Analysis
Given the attribution graph for the base input prompt, we now examine specific influential CLT features to understand their distinct computational roles and behavioral patterns in the greater-than task. To identify the most influential features, we rank all the edges by their attribution magnitude to the top 10 logits. For each logit we then take the top 16 features, resulting in a set of 160 "features of interest" (pre deduplication) on which we perform further analysis.
For each feature, we replicate Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.'s logit attribution analysis measuring each feature's contribution to the logits for all possible output years. Whereas the MLP neurons studied in Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. each contribute exactly one vector to the residual stream, a CLT feature is decoded into all subsequent layers. For our attribution analysis, we sum all later layers' decoder vectors. Formally, for a given input prompt, we computed the summed decoder vector for a feature $f$ at layer $\ell$ as:
where $a_{f}^{\ell}$ is the activation value of feature $f$ at layer $\ell$ and $ W_{dec,f}^{\ell,i}$ is the $f$th column of the decoder matrix from source layer $\ell$ to target layer $i$.
Following Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023., we measure the logit attribution $\text{logit-attr}(f,\ell, t)$ for token $t$ as the dot product between $v_{f}^{\ell}$ and the unembedding vector for $t$
High logit attribution scores indicate that a feature vector strongly promotes the corresponding digit token, while low (or negative) scores suggest the feature either weakly supports or actively suppresses that token's prediction.
For the visualizations below, we again follow Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. and compute heatmaps representing the input-output mapping computed by each feature. For each input year $\texttt{YY}$, we run a forward pass of the local replacement model on the prompt "The war lasted from the year 17$\texttt{YY}$ to 17", and cache the activations of all features of interest. For feature $f$ at layer $\ell$, we compute $\text{logit-attr}(f,\ell,\texttt{ZZ})$ as outlined above, where $\texttt{ZZ}$ ranges over possible two-digit year completions. These results then populate a years-by-years attribution matrix.
To restate the roles of different prompts in our analysis, we use a single prompt ( "The war lasted from the year 1711 to 17") to construct our graphs and select features, and then a collection of ~100 prompts "The war lasted from the year 17$\texttt{YY}$ to 17" for all $\texttt{YY}$ to analyze and interpret the selected features.
Results: Interpretable features
Of the discovered features, we hand selected a subset of features with particularly clear or interesting interpretations that are relevant to the task. We group these features into subcategories by perceived function. For each feature we provide the logit attribution heatmaps, showing the logit attribution scores from all valid input years to all valid predicted years. In addition to logit attribution heatmaps, we also include the maximum activating examples for all features.
Greater-than/large number features
The first and most influential group is the greater-than features, which constitute the primary computational components responsible for the model's numerical comparison behavior in this task. These features' max-activating examples demonstrate clear greater-than computational patterns, responding most strongly to numerically larger values in their input contexts. These features are often located in later layers and rank highest in terms of attribution strength to the respective logits.
Feature 425104
The highest-ranking input feature to the 18 output logit occurs in layer 8, and its max-activating examples are notably task-relevant: it consistently activates on larger years within dense chronological contexts, suggesting it has learned to identify numerically greater temporal values. This activation pattern directly aligns with the feature's computational role in the greater-than task, where it must distinguish between smaller and larger numerical values to appropriately suppress or promote year predictions.
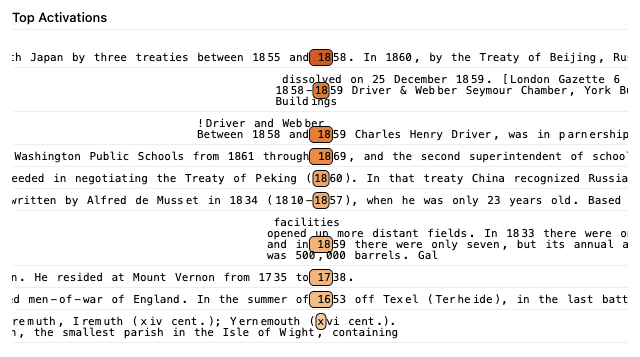
Note the interesting final example, where the feature responds to a later date written in Roman numerals rather than Arabic numerals, indicating that the model has learned semantic date representations beyond mere character pattern matching.
The attribution scores for this feature show a clear preference for promoting large numbers, particularly ones greater than 60. There's a transition from negative to positive attributions for predicted years greater than 12, which is expected given our feature-selection prompt "The war lasted from the year 1711 to 17". In an interesting contrast to the Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. heatmaps, though, there is no clear pattern across the rows of the matrix, indicating that the feature can promote, for example, 62, as response to 90, even though 90 > 62. The reason for the divergence between the max activating examples and the logit attributions is unclear, but may arise because the logit attribution measures the impact of a single feature in isolation, whereas max-activating examples show the feature's behavior in the full model context where all features interact.
![]()
Feature 407684
Feature 407684 demonstrates a similar behaviour, promoting predicted years greater than approximately 15 and heavily suppressing predicted years under 15 (again, expected given our prompt uses input year 11).
![]()
As with Feature 425104, the max-activating examples for Feature 407684 show consistent activation immediately before the largest numerical values in a sequence. However, this pattern extends beyond temporal contexts to include numerical values in commercial and quantitative settings (prices, percentages, measurements). This more-generalized occurrence suggests the feature represents a broader greater-than computational pattern that operates across diverse numerical contexts, not just chronological ones, while still serving the same fundamental role of distinguishing between smaller and larger values.

Feature 451291
While the previous features' max-activating examples showed clear greater-than behavior, their attribution heatmaps showed a puzzling lack of input-dependence. Feature 451291 demonstrates a clear preference for promoting large numbers, particularly predicted years greater than 39, but also exhibits notable input dependence, with certain input years producing zero logit attribution scores. Additionally, we also see localized pockets of promotion and suppression for certain predicted years, such as around 12 and 4 (promotion), and around 80 and 72 (suppression). This complex pattern suggests the feature could represent a more sophisticated computational logic than simple numerical comparison, potentially encoding multiple conditional rules or operating as a composite of several specialized numerical detectors.
![]()
Feature 451291 shares many max-activating examples with Feature 425104, and we similarly find activation immediately before larger numerical values in a sequence, demonstrating greater-than computation. However, unlike Feature 425104, it doesn't consistently activate for the largest value in the sequence.

Feature 461858
Feature 461858 demonstrates much more extreme input dependence, showing non-zero attribution only for input years between 6 and 14. Within this narrow range, the feature promotes predicted tokens greater than 10 up to approximately 30, after which it begins to actively suppress larger predictions, creating a highly specialized computational pattern that operates within specific numerical boundaries.
![]()
The max-activating examples confirm this pattern and demonstrate clear general greater-than computational behavior, with the feature consistently activating before larger numerical values in a sequence. However, this greater-than computation operates exclusively within the 10-30 range observed in the heatmap. Since this feature was discovered using the prompt "The war lasted from the year 1711 to 17" we can hypothesize that there are many similar features that would activate for different prompts, each responsible for narrow, specific greater-than behaviour.
Feature 349410
Feature 349410 demonstrates even more extreme input dependence, showing non-zero attribution only for input year 11 and heavily promoting predicted values around 11.
![]()
Consistent with the heatmap, the max-activating examples for Feature 349410 show consistent activation on the tokens before values under 30 across diverse contexts, including timestamps, dates, forum posts, and technical specifications. However, we see that, as opposed to the heatmap, it activates in preceding contexts beyond just the number 11 suggesting the feature responds to a broader range of numerical inputs than its highly specific logit attribution behavior would indicate.

Feature 402486
As an interesting example of unexpected behavior, we show Feature 402486, which demonstrates relatively high influence (ranking 14th out of 137 features) but exhibits a completely different – and seemingly incorrect with respect to the task — computational pattern. This feature only activates for input years under 27, systematically promoting predicted years in the same low range while suppressing larger numbers, effectively implementing an inverse greater-than mechanism that favors smaller numerical values.
![]()
The max-activating examples for this feature show consistent activation on tokens immediately preceding numbers under 31, which aligns well with the heatmap's preference for promoting smaller numerical values. However, the examples don't demonstrate the same strict input dependence observed in the attribution heatmap, suggesting the feature may have broader activation patterns in natural text than its task-specific behavior would predict. Interestingly, the feature appears to activate in diverse contexts including academic citations, legal documents, and technical specifications, indicating it may serve as a general detector for "small number contexts".
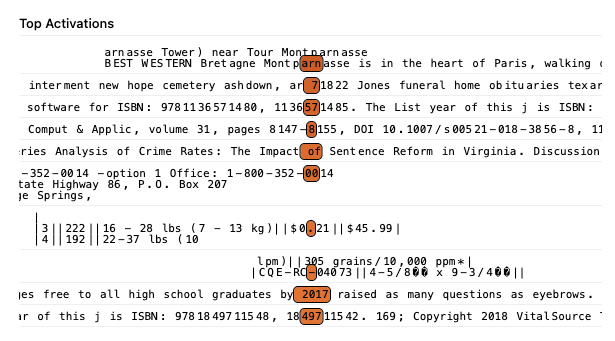
When comparing the results from Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. in Figure 1, we see some broad similarities, particularly in the columnar structure of our activation heatmaps. We also see notable differences, though, with some of the highest ranking CLT features' logit attribution heatmaps showing much less input dependence than Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.'s, and several other features activating on much more localized regions of input space.
Structured Number Features
We also identified a substantial group of features exhibiting highly specific numerical patterns, which we term Structured Number Features. These features demonstrate systematic preferences for numbers following particular mathematical or structural rules rather than simple comparisons.
Feature 399423
First, we found an interesting parity feature that demonstrates systematic numerical parity-based computation distinct from the greater-than mechanism. From the logit attribution heatmap, we see Feature 399423 consistently promotes even-numbered predictions while suppressing odd-numbered ones when activated by odd input years. It ranks 6th out of 146 features in terms of attribution strength to logit 20, demonstrating significant influence on the model's predictions.
![]()
![]()
The max-activating examples show the feature responds most strongly to tokens immediately preceding the second element in contrastive pairs, such as "and" in "pros and cons" or "or" in "right or wrong."

This feature demonstrates notable abstraction, appearing to encode a general representation of conceptual opposition or parity across diverse domains. The feature activates in contexts where producing a contrasting or opposite term would be semantically appropriate, including numerical parity relationships where odd inputs should yield even outputs. The activation pattern suggests this feature serves as a computational primitive for oppositional reasoning, providing a positive signal when the model encounters contexts requiring the generation of conceptually opposite or contrasting elements relative to previously established terms.
Feature 456115
Less abstract than the parity feature, Feature 456115, selectively promotes multiples of 5 (numbers ending in 5 or 0) and suppresses multiples close to 5 (numbers ending in 4, 6, 9 and 1) .
![]()
![]()
The max-activating examples for this feature reveal activation on tokens, predominately punctuation marks, that appear in proximity to the token 5, though this association is not entirely consistent across all instances.

Feature 475549
Feature 475549 demonstrates another structured numerical pattern, for certain inputs activating predominantly on input numbers ending in 1 and systematically promoting tokens that end in 2
![]()
Looking at the max-activating examples, we find this feature consistently activates on tokens preceding 2 across various contexts - in numbered lists, legal/technical documentation formatting, dates and timestamps, and sequential numbering systems.
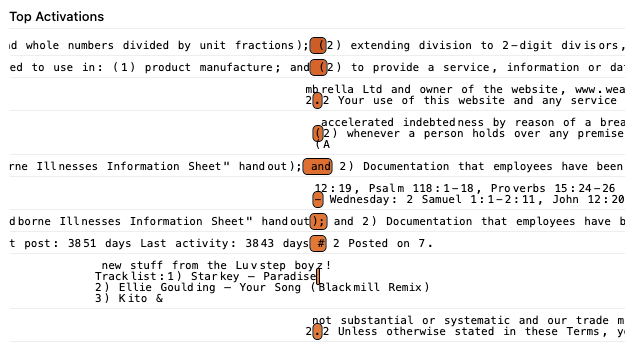
Discussion
In line with the results in Ameisen et al. [6]Circuit Tracing: Revealing Computational Graphs in Language Models[link]
Ameisen, Emmanuel, Lindsey, Jack, Pearce, Adam, Gurnee, Wes, Turner, Nicholas L., Chen, Brian, Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Ben Thompson, T., Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread. and Lindsey et al. [7]On the Biology of a Large Language Model[link]
Lindsey, Jack, Gurnee, Wes, Ameisen, Emmanuel, Chen, Brian, Pearce, Adam, Turner, Nicholas L., Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Thompson, T. Ben, Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread., we find that CLTs discover interpretable and relevant features for the greater-than task, and many of these features have recognizable similarities with those reported by Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.. Our features' max-activating examples show interesting variations in degree of abstraction, with some features seeming to be specific to dates, while others recruit more general machinery. Notably, CLTs are able to uncover relevant structure "out of the box," without requiring the elegant but labor-intensive experimental interventions used in the original Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. analysis.
However, considering all of our discovered features together, we observe a somewhat less clean representation space than Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.. For example, some of the structured-number features do not seem immediately relevant to the greater-than task, and don't have clear analogues in the Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023. results. And some greater-than features (e.g. Feature 349410) have extremely narrow input ranges, making them look more like special-case lookups than do Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.'s features. Interestingly, we can note some similarities to the heuristic features in the two-digit addition circuits described in Lindsey et al. [7]On the Biology of a Large Language Model[link]
Lindsey, Jack, Gurnee, Wes, Ameisen, Emmanuel, Chen, Brian, Pearce, Adam, Turner, Nicholas L., Citro, Craig, Abrahams, David, Carter, Shan, Hosmer, Basil, Marcus, Jonathan, Sklar, Michael, Templeton, Adly, Bricken, Trenton, McDougall, Callum, Cunningham, Hoagy, Henighan, Thomas, Jermyn, Adam, Jones, Andy, Persic, Andrew, Qi, Zhenyi, Thompson, T. Ben, Zimmerman, Sam, Rivoire, Kelley, Conerly, Thomas, Olah, Chris, and Batson, Joshua, 2025. Transformer Circuits Thread.. Developing a general understanding of CLT number representation across tasks could be a worthwhile goal of further investigation. In particular, understanding how CLT number representations relate to those found in non-sparse models, for example, the helical representations found in Kantamneni & Tegmark [8]Language Models Use Trigonometry to Do Addition[link]
Subhash Kantamneni and Max Tegmark, 2025. could be a useful case study in the ways that geometrically structured representation spaces change under sparse replacement.
Overall, our results demonstrate that CLTs can successfully identify interpretable computational components in well-understood tasks, while also revealing novel features like abstract parity detectors that point toward richer representational structures than previously recognized.
Limitations and future work
For many features, we found discrepancies between the logit attribution heatmaps and the max-activating examples. Specifically, for Feature 425104, the max-activating examples display clear input-date dependence, promoting the largest year in an input sequence, while the logit heatmap shows a weak preference for output years greater than 12, and a strong preference for output years greater than 60, largely independently of the input year. Conversely, the heatmap for Feature 349410 demonstrates clear input dependence, showing non-zero attribution only for input year 11, while the max-activating examples include a range of input years.
The reason for this divergence is unclear. We can speculate that it stems from the fact that logit attribution considers each feature in isolation, not accounting for the ways features interact in the full model context. Additionally, as a general caveat, the logit attribution techniques we used were designed for and validated in Transformers, and may not transfer directly to CLTs. For example, unlike Transformers, each CLT feature contributes multiple vectors to the residual stream.
A second limitation is that all our analyses used features selected with respect to a single prompt. It's possible that aggregating feature scores over multiple prompts would weed-out some distractor features and isolate a cleaner circuit more similar to Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023.'s.
Turning to future work, many more CLT explorations are possible in the greater-than task. To facilitate comparison with Hanna et al. [1]How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model[link]
Michael Hanna, Ollie Liu, and Alexandre Variengien, 2023., we limited our analysis to features at the final token position, since these support logit attribution. But in doing so, we haven't taken advantage of one of the biggest strengths of CLTs: their ability to trace interactions between positions. It would be interesting, for example, to study the mechanisms by which the noun in "[noun] lasted from 17$\texttt{YY}$ to 17" influences the final logits - presumably nouns with longer durations skew the output to larger numbers.